こんにちは、デジタルボーイです。今回は機械学習や統計モデルの初めの一歩とも言える、単回帰分析について、Pythonとscikit-learnを使い、初歩の初歩について解説したいと思います!

デジタルボーイです。
データサイエンス歴20年以上のおっさんです。中小企業診断士として、データサイエンス、WEBマーケティング、SEOに関するデータ分析、コンサルティングの仕事をしています。自己紹介の詳細はコチラ
単回帰モデルとは?
回帰分析には実はさまざまなモデルがありますが、その中でももっとも基本となるモデルが線形回帰モデル(Linear Regression)です。また、特に一つの変数(データ項目)で一つの変数を予測する回帰モデルを単回帰分析といいます。これは、数値データの関係を直線で表すシンプルなモデルです。ちなみに複数の変数で一つの変数を予測する回帰モデルは重回帰分析と言います。
予測のメカニズムの直感的理解
例として、広告費と売上の関係を「回帰分析」を当てはめてみましょう。回帰分析と、ある変数(この場合は広告費)が別の変数(売上)にどのような影響を与えているかを直線関係に当てはめることで予測する方法です。特に単回帰分析では1つの要因と結果の関係に焦点を当てます。
以下のように広告費が上がると、大まかに売上高も上がるような関係が図からわかります。
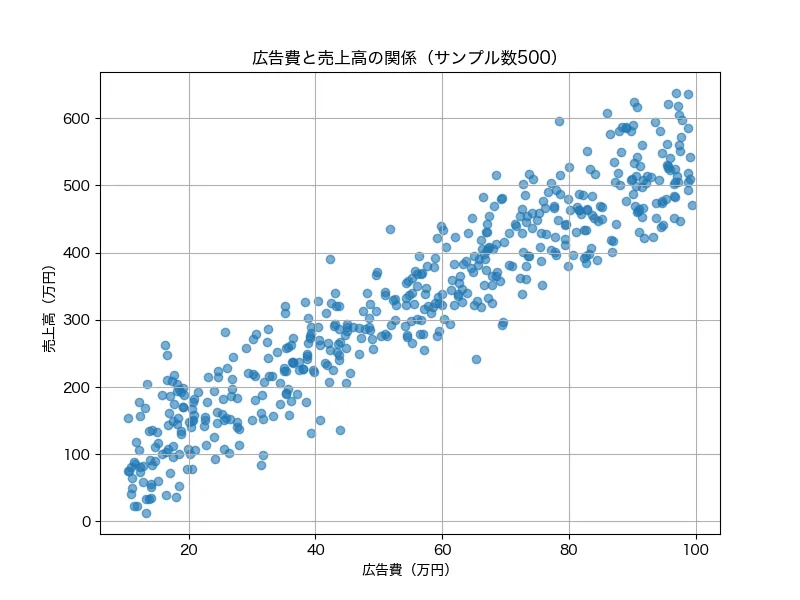
回帰分析では、このような関係に対して、「だったら直線を当てはめてみて、予測できるんじゃない?」という考えに基づいたモデルです。
で、実際にこのデータに回帰直線を引くと、次のようになります。
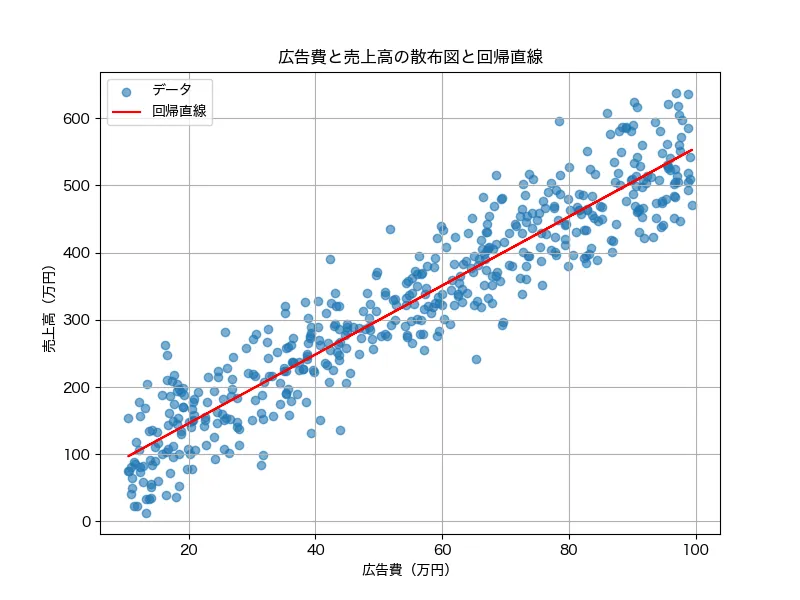
この回帰直線は、データがばらついているにも関わらず、最も「いい感じに」一本の線を引くための手法ともいえます。このようにいい感じに先を引くことで、「将来的に広告費をいくら投入したら売上がどれくらいになるか」を予測するために、回帰分析が使えます。
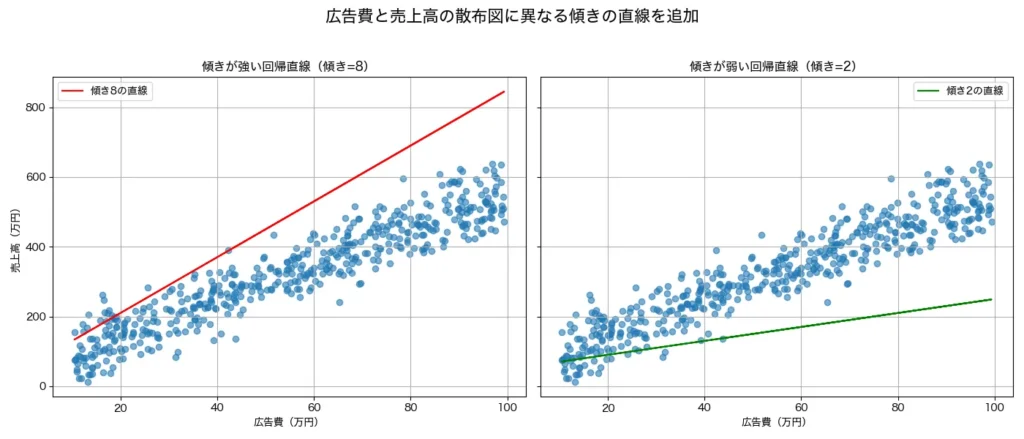
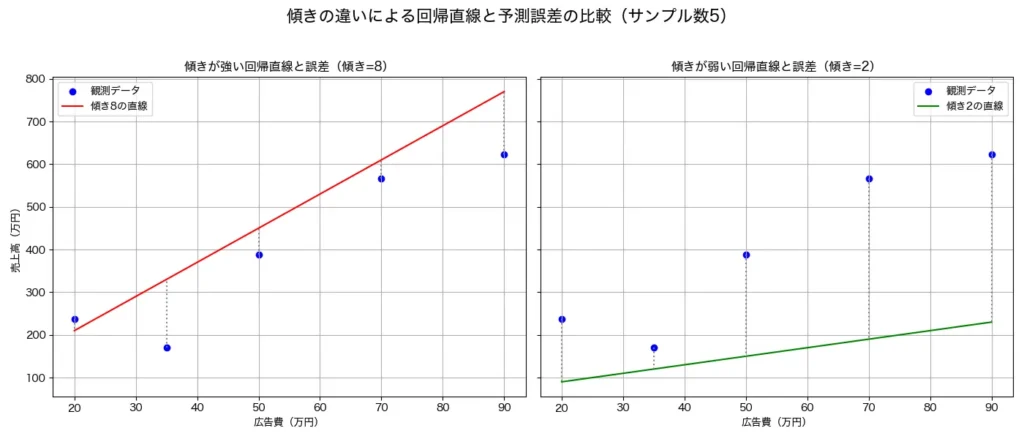
で、回帰分析が、いい感じに直線を引いてくれるからこそ、モデルを予測に使えると言う点はとても重要です。極端な話、次の左図や右図のように場違いな直線を引いてしまっては、とてもじゃないですが、予測に使えまよね。。。
では、どうやって、「いい感じ」に直線を引くのでしょうか?そのメカニズムを直感的に理解するための図が以下です。
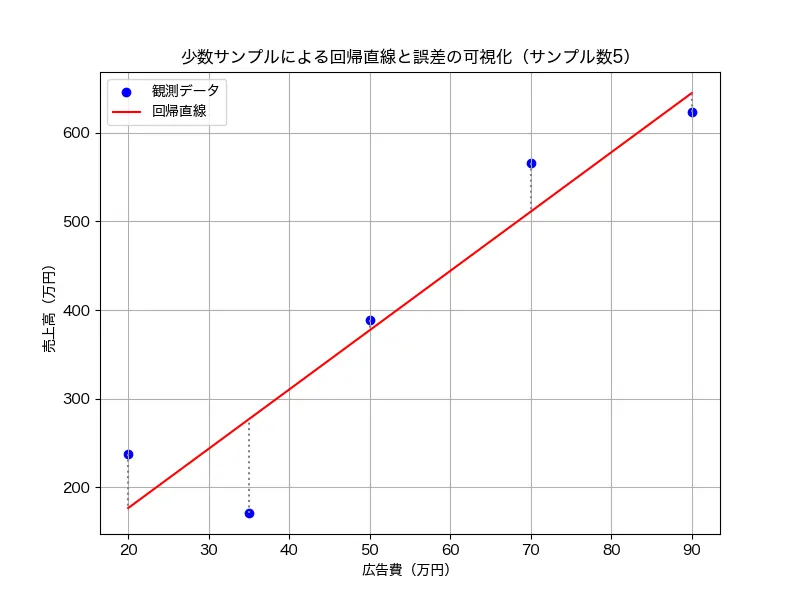
例として、5つのデータ点に絞って、回帰直線を引いてみました。また、各点から回帰直線に垂線を引っ張った直線を点線で表しています。この回帰直線に引いた垂線の長さがもっとも短くなるように回帰直線をが引くことで、その回帰直線は「いい感じの直線が引けた」と判断するのが回帰分析のメカニズムになります(正確に言うと、「すべての点から引いた垂線の長さを2乗し、その合計値が最小となる直線」です)。
例えば、次のように点から上に行きすぎたり、下に行きすぎた直線は明らかに、垂線が長いため、良い回帰直線とはいえませんね!また、垂線の長さを2乗する意図は、プラス方向とマイナス方向の垂線の長さを相殺されないために、全ての垂線の長さをプラス方向に調整するためです。
このように、回帰分析は単に「関係があるかどうか」を見るだけでなく、「どの程度の関係があるのか」「予測の信頼性はどうか」といった実践的な判断材料を与えてくれる強力な手法です。特に広告の費用対効果を考える場面では、意思決定において欠かせない分析手段といえるでしょう。
モデル式
簡単に、回帰分析のモデル式を見ておきましょう。予測される売上高(売上高の予測値)は、広告費との関係によって次のように表されます。
$$
{\text{売上高の予測値}} = \beta_0 + \beta_1 \times \text{広告費}
$$
ここで、\( \beta_0 \)は直線の切片であり、\( \beta_1 \) は直線の傾きになります。この2つの値を直線のパラメータと言います。
このパラメータをどのように推定するのかと言うと、先ほどの点と直線と垂線の関係を思い出していただきましょう。「予測された売上高と実際の売上高の誤差(垂線の長さ)の二乗和を最小にすること」これが、回帰分析のパラメータを最小にするためのアルゴリズムになります。
以上が簡単な、回帰モデルのメカニズムでした。それでは、次から実際にpythonを使って分析をして行ってみましょう。
今回の分析の目的とゴール
今回はScikit-learnの「ボストン住宅価格データセット」を使い、住宅価格と特徴量の関係を単回帰モデルで分析します。
分析の目的:
「住宅の価格がどの要素(広さ・部屋数・犯罪率など)に影響されるのか?」を理解し、住宅価格を予測できるようにする。
分析のゴール:
- データを可視化し、どの特徴量が価格と関係しているか直感的に理解する
- 線形回帰モデルを作成し、予測精度を評価する
- 結果をグラフ化し、モデルの出力を解釈する
必要なライブラリのインストールと準備
今回必要なライブラリです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.datasets import fetch_california_housingコードの解説
- import XXX でこれから必要なライブラリを読み込んでいます。
- from XXX import YYY はXXXというライブラリの中のYYYというクラス(機能)を読み込んでいます。
- これらはのライブラリやクラスは後のコードで利用します。
もしインストールしていない場合はpipでインストールしてみてください。pipを使ったインストール方法はこちらになります。



データの読み込みと概要の確認
Scikit-learnの「California housing dataset(カリフォルニア住宅価格データ)」を使用します。
# データを取得
data = fetch_california_housing()
df = pd.DataFrame(data.data, columns=data.feature_names)
df["Price"] = data.target # 住宅価格を追加
# データの概要
print(df.head())
print(df.describe())コードの解説
- カリフォルニアの住宅価格データを取得するには、まず
fetch_california_housing()を使用してデータを取得し、 - その後
pd.DataFrame(data.data, columns=data.feature_names)を用いて Pandas のデータフレームに変換します。 - さらに、住宅価格情報を
df["Price"] = data.targetで追加します。 - データの内容を確認するため、
df.head()を使って先頭5行を表示し、 df.describe()によって各特徴量の統計情報(平均値、標準偏差、最大・最小値など)を出力します。- これにより、データの基本的な分布や傾向を把握し、分析や機械学習の前処理に活用できます。
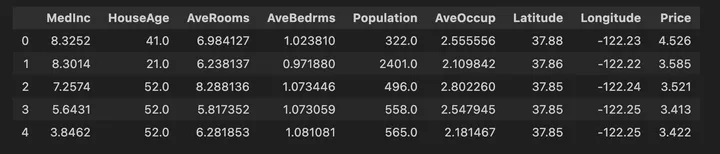
先頭の5行のデータは、df.head()で、こんな感じで出されます。
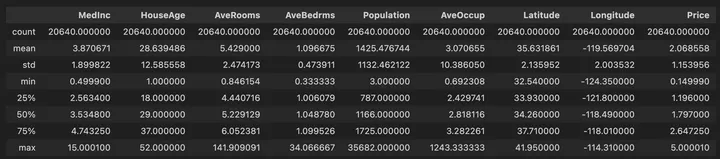
df.describe()では、各変数の基本的な統計量が次のように出力されます。
このデータには、カリフォルニア州の住宅に関する情報が入っています。
主な特徴量:
MedInc(地域の中央値年収)HouseAge(住宅の築年数)AveRooms(平均部屋数)AveOccup(世帯あたりの平均居住者数)
データの可視化
まず、住宅価格と特徴量の関係を可視化してみましょう。
特に影響がありそうなMedInc(中央値年収)とPrice(住宅価格)をプロットします。
plt.rcParams["font.family"] = "Hiragino sans"
plt.scatter(df["MedInc"], df["Price"], alpha=0.5)
plt.xlabel("収入の中央値")
plt.ylabel("住宅価格")
plt.title("収入の中央値と住宅価格")
plt.show()コードの解説
plt.rcParams["font.family"] = "Hiragino sans":グラフのフォントをMacフォントの「Hiragino Sans」に設定し、日本語のラベルを適切に表示できるようにする。Windowsの場合は、plt.rcParams[“font.family”] = “Meiryo”などにする。plt.scatter(df["MedInc"], df["Price"], alpha=0.5):収入の中央値 (df["MedInc"]) と住宅価格 (df["Price"]) の散布図を描画する。alpha=0.5により、プロットの透明度を50%に設定し、データ点の重なりを視認しやすくする。plt.xlabel("収入の中央値"):x軸のラベルを「収入の中央値」に設定する。plt.ylabel("住宅価格"):y軸のラベルを「住宅価格」に設定する。plt.title("収入の中央値と住宅価格"):グラフのタイトルを「収入の中央値と住宅価格」に設定する。plt.show():作成した散布図を表示する。
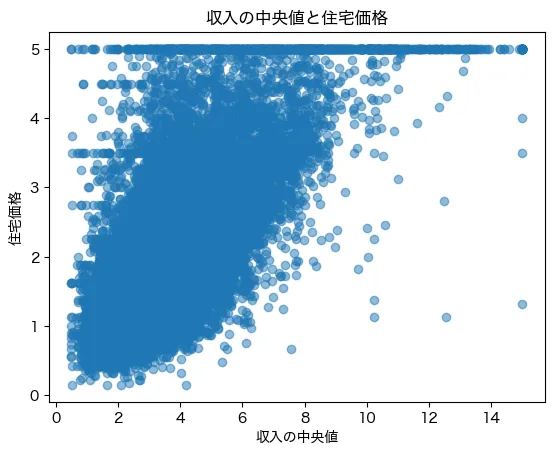
縦軸の住宅価格は1,2,3,4,5となっています、おそらく10万ドル単位なのでしょう。また、5のところ(50万ドル)のところで上限が切られているようですね。本来は5以上のデータとして持っているのでしょうが、上限を5に置き換えたデータとしているようです。概ね、収入が上がれば上がるほど、住宅価格は高くなる傾向が見えました。
予想:
所得が高いほど、住宅価格も高くなりそうですね!
この関係を線形回帰モデルで分析してみましょう。
単回帰モデルの作成と学習
MedInc(地域の中央値年収)を説明変数(X)、Price(住宅価格)を目的変数(y)として、単回帰モデルを作ります。
# 特徴量とターゲットを設定
X = df[["MedInc"]]
y = df["Price"]
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの作成と学習
model = LinearRegression()
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
コードの解説
X = df[["MedInc"]]で特徴量として収入の中央値を設定し、y = df["Price"]でターゲット変数として住宅価格を指定する。train_test_split(X, y, test_size=0.2, random_state=42)を用いて、データを訓練用(80%)とテスト用(20%)に分割し、random_state=42によりランダムサンプリング用の乱数の種を指定している。model = LinearRegression()で線形回帰モデルを作成し、model.fit(X_train, y_train)によって訓練データを用いて学習を行う。- 最後に、
y_pred = model.predict(X_test)により、テストデータを使って住宅価格の予測を行う。
結果の可視化
モデルの予測を実際のデータと比較してみます。
plt.scatter(X_test, y_test, alpha=0.5, label="Actual")
plt.scatter(X_test, y_pred, alpha=0.5, label="Predicted", color="red")
plt.xlabel("収入の中央値")
plt.ylabel("住宅価格")
plt.title("収入の中央値と住宅価格")
plt.legend()
plt.show()コードの解説
plt.scatter(X_test, y_test, alpha=0.5, label="Actual")で実測値の散布図を描画し、plt.scatter(X_test, y_pred, alpha=0.5, label="Predicted", color="red")により予測値の散布図を赤色で追加する。plt.xlabel("収入の中央値")で x 軸のラベルを設定し、plt.ylabel("住宅価格")で y 軸のラベルを設定する。plt.title("収入の中央値と住宅価格")によってグラフのタイトルを追加し、plt.legend()で凡例を表示することで、実測値と予測値の違いを明確にする。- 最後に
plt.show()でグラフを描画する。
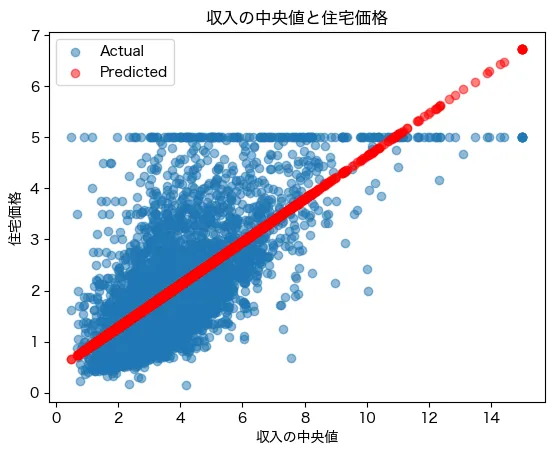
- 青点:実際のデータ
- 赤点:モデルの予測結果
予測は全体的な傾向をとらえていますが、実際のデータとは少しズレがある部分もあります。
モデルの評価
モデルの精度を評価するために、平均二乗誤差(MSE)と決定係数(R2)を計算します。
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")
rmse = np.sqrt(mse) # MSE の平方根を取る
print(f"Root Mean Squared Error (RMSE): {rmse:.4f}")
r2 = model.score(X_test, y_test)
print(f"決定係数 (R²): {r2:.4f}")
コードの解説
mse = mean_squared_error(y_test, y_pred)で平均二乗誤差(MSE)を計算し、print(f"Mean Squared Error: {mse:.2f}")で小数点以下2桁で表示する。MSE は誤差の二乗平均を表し、0 に近いほど精度が高いことを意味する。rmse = np.sqrt(mse)で MSE の平方根を計算し、print(f"Root Mean Squared Error (RMSE): {rmse:.4f}")で小数点以下4桁で表示する。RMSE は元のターゲット変数と同じ単位を持ち、誤差の平均的な大きさを直感的に把握しやすい。r2 = model.score(X_test, y_test)で決定係数(R²スコア)を計算し、print(f"決定係数 (R²): {r2:.4f}")で小数点以下4桁で表示する。R² は 1 に近いほどモデルの説明力が高く、0 に近いほどデータをうまく説明できていないことを示す。
結果はこんな感じでした。
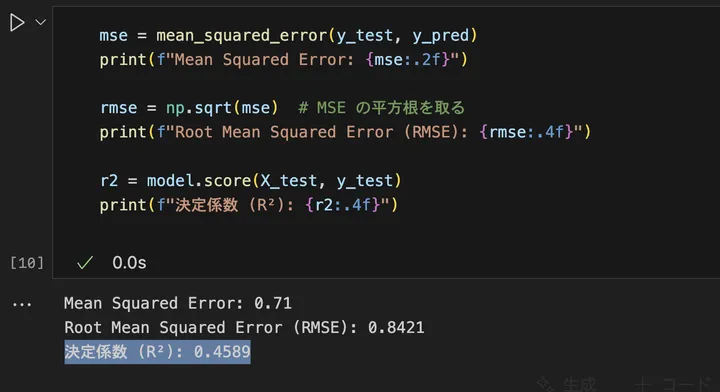
MSEが小さいほど、予測の誤差が少なく精度が良いことを意味し、決定係数は1に近いほどモデルの説明力が高いことを意味しています。
MSEが: 0.71 というのは、モデルの予測値と実測値の誤差の二乗平均を示す指標が、0.71とう意味です。MSE は次のように計算されます。
$$ MSE = \frac{1}{n} \sum (y_{\text{実測値}} – y_{\text{予測値}})^2 $$
ここで、0.71 という値は、平均すると 予測値と実測値の誤差の二乗が 0.71 であることを意味します。MSE の値は 0 に近いほど予測の精度が高い ことを示し、大きいほど誤差が大きいことを意味します。
ただし、MSE は二乗された単位で表されるため、元のデータのスケールと異なります。そのため、より解釈しやすい指標として Root Mean Squared Error (RMSE) も上のコードでは計算しています。RMSE は MSE の平方根を取ったもので、同じ単位で解釈できます。
$$ RMSE = \sqrt{MSE} = \sqrt{0.71} \approx 0.84 $$
この場合、住宅価格の予測誤差の平均的な大きさは 0.84(単位: 10万ドル) であると解釈できます。
決定係数(R²)が 0.4589 という結果は、このモデルが 住宅価格の変動の約 45.89% を説明できる ことを意味します。R² は 1 に近いほどモデルの説明力が高く、0 に近いほどデータをうまく説明できていない ことを示します。今回の値 0.4589 は中程度の精度であり、モデルの予測性能はある程度あるものの、まだ改善の余地があることを示唆しています。
モデルの予測精度についてはいろいろ人によって解釈が異なりますが、僕がもし実際のコンサル場面でこの予測精度だった場合は、「一般的にはモデル精度は高くない。ただし、一発目の予測モデルでかつ、変数を1つだしか使っていない割には悪くない、これからモデルの改良を加えることで、そこそこの予測精度は出せそう」と考えます。
まとめ
本記事では、Scikit-learnを使って線形回帰モデルを実装し、データを視覚的に理解しました。
学んだこと
- 線形回帰とは? → 直線でデータの関係を表すシンプルなモデル
- 現実での活用例 → 住宅価格、売上、体重などの予測
- 実装方法 → Scikit-learnの
LinearRegressionを使う - 結果の解釈 → グラフを見て、予測と実際の違いを確認
- 評価方法 → MSEで精度を測る
単回帰モデルは、データ分析の最初の一歩としてとても良いモデルです。次は重回帰モデルにチャレンジしてみましょう!