こんにちは、デジタルボーイです。今回はLightGBMをMacOSにインストールし、モデルを構築する手順を解説したいと思います。

デジタルボーイです。
データサイエンス歴20年以上のおっさんです。中小企業診断士として、データサイエンス、WEBマーケティング、SEOに関するデータ分析、コンサルティングの仕事をしています。自己紹介の詳細はコチラ
LightGBMとは?
LightGBM(ライト・ジービーエム)は、Microsoftが開発した勾配ブースティング(Gradient Boosting)系のアルゴリズムです。決定木をベースにしており、「速い・精度が高い・扱いやすい」の三拍子そろったモデルとして、多くのコンペや実務の現場で使われています。僕自身もとりあえず精度を上げたいという実務で予測をする場面では、lightgbmを使っています。
特徴をざっくり挙げると、こんな感じです!
- データが多くても高速に処理できます(数百万行でもOK)。
- 少しの特徴量でも、複雑な非線形な関係を学習できます。
- 欠損値があっても、自動でうまく扱ってくれます。
- 分類・回帰・ランキングなど、さまざまな問題に対応できます。
LightGBMでは、モデルが「どの特徴量をどれだけ使って予測に貢献したか」を可視化することができます。これを「特徴量重要度(feature importance)」と呼びます。重要度をグラフ化したのが以下になります。
このグラフを見ると、モデルが「何を見て判断しているのか?」が直感的にわかりますね!
また、LightGBMは複数個の決定木というアルゴリズムを連結させることで予測するのですが、その決定木のアウトプットも出力することができます。
LightGBMのこうした可視化機能は、モデルを「ただのブラックボックス」にせず、「なんとなく中身がわかるグレーな箱」にしてくれるところが嬉しいポイントです!
ざっくり、LightGBMの予測メカニズム
決定木がベース
LightGBMは決定木という予測モデルがベースとなっています。決定木とは、質問を繰り返しながら最終的な答えを導く「木の形をした予測モデル」です。たとえば、「1日の平均摂取カロリー数は2500kcal以上か?」とか「体重は70kg以上か?」といった条件を分岐点にして、糖尿病のリスクを予測するようなイメージです。
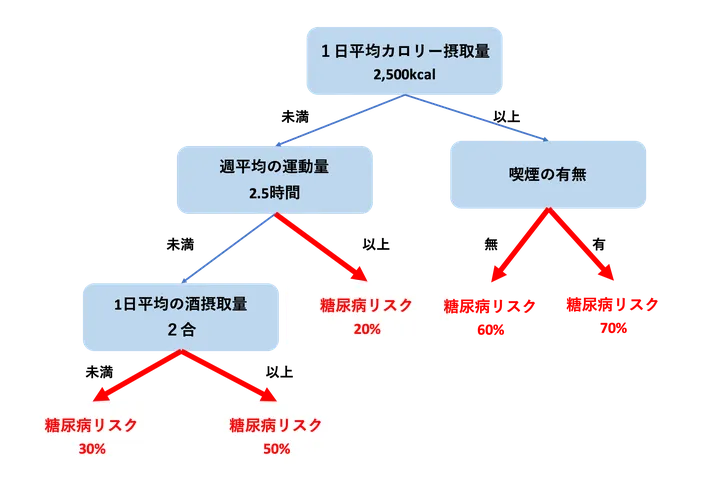
条件に合う枝をたどっていけば、最後に「予測値」や「分類結果」にたどり着きます。あみだくじみないなものですね!1つ1つの判断がシンプルなので、モデルの仕組みが直感的に理解しやすいのが特徴です。分類や回帰のどちらにも使える上、特徴量の重要度を視覚化することもできます。ただし、この決定木だけだと、予測精度がイマイチだったり、過学習を起こしやすかったりと、予測モデルとして精度をあげようとした場合、ちょっと難しいことが多々あります。
勾配ブースティングは予測モデルを連結させるテクニック
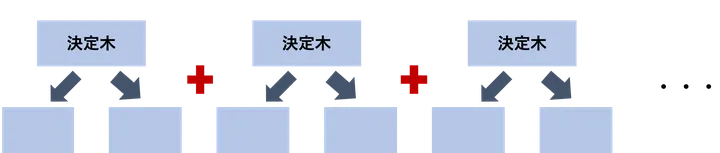
勾配ブースティングとは、予測モデルを連結させ、連結の都度、予測の誤差を少しずつ修正しながら精度を高めていく機械学習手法です。最初にモデルを使って予測を行い、そこで生じた誤差(残差)を次のモデルが学習し、さらにその誤差を次のモデルが補う…というように、複数のモデルを「たし算」するように重ねていきます。

これにより、1つのモデルでは捉えきれなかった複雑なパターンを徐々に学習できるのが強みです。特に予測精度が高く、実務でもよく使われる手法で、LightGBMでも採用しています。
LightGBMは決定木をブーストさせている
LightGBMの内部では複数の決定木を勾配ブースティングを使い連結させることで、予測誤差を段階的に補正していくことで予測するモデルです。
大きな特徴は、「Leaf-wise(葉優先)」という木の成長戦略を採用しており、精度が高まりやすい一方で、過学習に注意が必要です。また、大規模データや高次元データにも強く、学習速度が非常に速い点も実務で重宝される理由です。さらに、カテゴリ変数を自動で処理できる、並列学習に対応している、特徴量の重要度を可視化できるなど、便利な機能も豊富です。Kaggleなどの機械学習コンペでも高成績モデルによく使われます。精度とスピードのバランスが良いモデルといえますね!
MacへのLightGBMのインストール
インストール手順はLightGBMの公式サイトのインストールガイドに沿って解説します。
LightGBMは、マイクロソフトが開発した、強力な予測モデルライブラリです。特にPythonに特化したライブラリでもなく、また、Macへのインストールということもあり、ちょっとインストールにはめんどくさい点があります。ここでは、macOS向けのインストール手順を解説します。windowsやlinuxの方はインストールガイドを参考にしてください。
LightGBMは内部ではPythonだけでなく、C++という言語で書かれたプログラムが動いています。そのため、LightGBMをインストールしたり動かしたりするには、Pythonだけでなく、そのC++の部分を正しく扱うためのツールや仕組みも必要になります。ここで必要になるのが「cmake」と「libomp」です。
ここで、「cmake(シーメイク)」は、C++で書かれたプログラムをコンピュータが実行できる形に変えるための「ビルド」という作業を行うときに使うツールです。LightGBMをPythonから使う際でも、内部でこのビルドが必要になる場合があり、そのためにcmakeが必要です。
次に、「libomp(リブ・オーエムピー)」は、「OpenMP(オープンエムピー)」という仕組みをMacで使えるようにするライブラリです。OpenMPは、LightGBMがデータの処理を速くするために使っている“並列処理”を実現するための技術です。しかし、macOSに標準で入っているコンパイラ(Apple Clang)は、このOpenMPを最初からサポートしていないため、自分で後から追加する必要があります。それが「libomp」です。
ということで、話が長くなりましたが、lightgbmのインストールの前に、必ず、「cmake」と「libomp」をターミナルからインストールしておきましょう。ターミナルから以下のコマンドを実行してください。
brew install cmake libomp続いて、lightgbmを以下のようにpipからインストールすればOKです。
pip install lightgbm
これでインストール完了です!
必要なライブラリのインポート
LightGBMを使って機械学習モデルを作るためには、いくつかのPythonライブラリが必要です。もしまだインストールしていない場合は、事前に pip install を使ってインストールしておきましょう。lightgbmのmacへのインストール方法は上述。
pip install pandas scikit-learn
pipを使ったインストール方法がわからない場合はこちらをご覧ください。



では、必要なライブラリをインポートしましょう。
import lightgbm as lgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errorデータの項目の確認と概要の確認
ここでは、LightGBMでのモデル構築の前に、どんなデータを使うかを確認しておきましょう。今回は、機械学習の練習用としてよく使われるカリフォルニア住宅価格データセットを使います。このデータは1990年ごろのカリフォルニア州の住宅に関する情報をまとめたものです。各地域の人口、世帯数、平均部屋数などの情報と、目的変数として「住宅の中央値(Median House Value)」が含まれています。
from sklearn.datasets import fetch_california_housing
import pandas as pd
# データをDataFrame形式で読み込む
data = fetch_california_housing(as_frame=True)
# 特徴量と目的変数に分ける
X = data.data
y = data.target
# 項目の確認(最初の5行を見る)
print(X.head())
# データの構造を確認
print(X.info())
# データの統計的な要約を見る
print(X.describe())
コード解説
print(X.describe())
各列の平均・標準偏差・最大値・最小値など、統計的な基本情報を表示しています。
from sklearn.datasets import fetch_california_housing
カリフォルニア住宅価格データセットを取得するための関数を読み込んでいます。
data = fetch_california_housing(as_frame=True)
データをpandasのDataFrame形式で取得できるようにしています。
X = data.data
入力となる特徴量(部屋数や人口密度などの説明変数)を X に代入しています。
y = data.target
出力(目的変数)である「住宅価格の中央値」を y に代入しています。
print(X.head())
最初の5行を表示して、どんな特徴量が含まれているかを確認しています。
print(X.info())
各列の型や欠損値の有無など、データの構造的な情報を出力しています。
このデータには、例えば「AveRooms(平均部屋数)」や「MedInc(中間所得)」といった特徴量があます。
アウトプットはこんな感じです。
まず、データの初めの5件
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | |
|---|---|---|---|---|---|---|---|---|
| 0 | 8.3252 | 41 | 6.98413 | 1.02381 | 322 | 2.55556 | 37.88 | -122.23 |
| 1 | 8.3014 | 21 | 6.23814 | 0.97188 | 2401 | 2.10984 | 37.86 | -122.22 |
| 2 | 7.2574 | 52 | 8.28814 | 1.07345 | 496 | 2.80226 | 37.85 | -122.24 |
| 3 | 5.6431 | 52 | 5.81735 | 1.07306 | 558 | 2.54795 | 37.85 | -122.25 |
| 4 | 3.8462 | 52 | 6.28185 | 1.08108 | 565 | 2.18147 | 37.85 | -122.25 |
「中間所得(MedInc)」「住宅の築年数(HouseAge)」「平均部屋数(AveRooms)」「平均寝室数(AveBedrms)」「人口(Population)」「平均世帯人数(AveOccup)」「緯度(Latitude)」「経度(Longitude)」といった住宅や地域の特徴を数値で表しています。
続いて、データに格納されている概要
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 MedInc 20640 non-null float64
1 HouseAge 20640 non-null float64
2 AveRooms 20640 non-null float64
3 AveBedrms 20640 non-null float64
4 Population 20640 non-null float64
5 AveOccup 20640 non-null float64
6 Latitude 20640 non-null float64
7 Longitude 20640 non-null float64
dtypes: float64(8)
memory usage: 1.3 MB
Noneこのデータフレームは全8列・20,640行から成り、すべての列が欠損のない浮動小数点型(float64)の数値データで構成されていることがわかります。
続いて、要約統計量です。
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | |
|---|---|---|---|---|---|---|---|---|
| count | 20640 | 20640 | 20640 | 20640 | 20640 | 20640 | 20640 | 20640 |
| mean | 3.87067 | 28.6395 | 5.429 | 1.09668 | 1425.48 | 3.07066 | 35.6319 | -119.57 |
| std | 1.89982 | 12.5856 | 2.47417 | 0.473911 | 1132.46 | 10.386 | 2.13595 | 2.00353 |
| min | 0.4999 | 1 | 0.846154 | 0.333333 | 3 | 0.692308 | 32.54 | -124.35 |
| 25% | 2.5634 | 18 | 4.44072 | 1.00608 | 787 | 2.42974 | 33.93 | -121.8 |
| 50% | 3.5348 | 29 | 5.22913 | 1.04878 | 1166 | 2.81812 | 34.26 | -118.49 |
| 75% | 4.74325 | 37 | 6.05238 | 1.09953 | 1725 | 3.28226 | 37.71 | -118.01 |
| max | 15.0001 | 52 | 141.909 | 34.0667 | 35682 | 1243.33 | 41.95 | -114.31 |
たとえば「平均的な中間所得は約3.87(単位:万ドル)」で、「最も部屋数が多い住宅は141部屋超え」といったように、地域ごとの差がかなり大きいことが読み取れます。
分析の目的とゴール
今回の分析の目的は、カリフォルニア州の各地域における住宅価格の中央値を予測することです。与えられた特徴量、たとえば中間所得(MedInc)や平均部屋数(AveRooms)などの情報から、「この地域の住宅価格はどのくらいになりそうか?」という未来の価格を推定します。
ということで、今回の分析のゴールは「与えられた情報をもとに、住宅の価格(中央値)をなるべく正確に予測できるモデルを作る」ということにします。
目的変数は連続値なので、今回の問題は「回帰問題」と呼ばれるタイプになります。分類ではないので、「正解・不正解」というよりも、「どれだけ近い値を予測できたか」が重要になってきます。
LightGBMモデルの実装
PythonでLightGBMを使う際には、主に2つの方法があります:
LGBMRegressor(scikit-learn ライクな高レベルAPI)lgb.train(LightGBMネイティブの低レベルAPI)
LGBMRegressor は scikit-learn 風のインターフェースを提供する高レベルAPIです。fit() や predict() といった関数を使って学習や予測を行えるため、scikit-learn に慣れている人であれば直感的に使えます。また、GridSearchCV や Pipeline などの scikit-learn のツールともスムーズに連携でき、クロスバリデーションやハイパーパラメータチューニングも簡単に行えます。
一方、lgb.train は LightGBM のネイティブAPIで、より柔軟に高度な設定が可能です。例えば、GPUの使用、バイナリ形式のデータ保存、高度な early stopping 制御、カスタム目的関数や評価関数の定義などができます。ただし、lgb.Dataset という専用の形式にデータを変換しなければならないなど、初心者にとってはやや取っ付きにくい印象があるかもしれません。
簡単にまとめると、使いやすさ重視なら LGBMRegressor、柔軟性と高機能を求めるなら lgb.train が向いています。また、僕自身は実務上でlgbmを使う際は、sklearnの他のモデルと比較しながら使うことが多いため、LGBMRegressorを使っています。ということで、この記事では、この2つの違いを簡単に比較したうえで、今回はより手軽に使える LGBMRegressor を使って実装例を紹介します。
それでは、LGBMRegressorを使ってモデルの学習を行ってみましょう。まずはデータを訓練用とテスト用に分割し、その後、LGBMRegressorに学習させます。ここではまだ評価指標の計算は行わず、モデルの構築と学習部分のみを行います。
import lightgbm as lgb
from sklearn.model_selection import train_test_split
# データの分割(80%を訓練、20%をテスト)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの初期化(代表的なパラメータを指定)
model = lgb.LGBMRegressor(
objective='regression', # 回帰問題を指定
boosting_type='gbdt', # 勾配ブースティング(通常はこれでOK)
n_estimators=100, # 決定木の数(多いほど複雑なモデルになる)
learning_rate=0.1, # 学習率(小さくすると学習はゆっくりだが精度は高まりやすい)
max_depth=6, # 各決定木の深さ(過学習を防ぐ)
num_leaves=31, # 1つの木に生やせる分岐の数(性能と速度のバランスをとる)
random_state=42 # 乱数シード(再現性のために指定)
)
# モデルの学習
model.fit(X_train, y_train)
コード解説
(デフォルト値を利用する場合、パラメータは指定しなくてもいいのですが、今回は学習目的なのであえて明示しています。)
- objective=’regression’
目的関数の指定です。’regression’ は回帰用で、連続値を予測します。
デフォルト値: ‘regression’ - boosting_type=’gbdt’
使用するブースティングの種類を指定します。’gbdt’ は一般的な勾配ブースティング方式です。普通はこのままでOKです。
デフォルト値: ‘gbdt’ - n_estimators=100
決定木(弱学習器)の本数を指定します。増やすと表現力が上がる一方で過学習のリスクもあります。
デフォルト値: 100 - learning_rate=0.1
1本ごとの木がどれだけ最終予測に影響するかを調整する値です。小さいほど学習は慎重になります。
デフォルト値: 0.1 - max_depth=6
各決定木の深さの最大値を制限します。浅いと単純なモデルに、深いと複雑で過学習しやすくなります。
デフォルト値: -1(= 制限なし) - num_leaves=31
1本の木が持てる葉の数(分岐の数)を指定します。これが多いと表現力は上がりますが、複雑にもなります。
デフォルト値: 31 - random_state=42
実行ごとの結果のバラつきを抑えるための乱数シードです。モデルの再現性が欲しいときに指定します。
デフォルト値: None(指定しないと毎回変わる)
こんな感じで結果が出ると思います。
[LightGBM] [Warning] Accuracy may be bad since you didn't explicitly set num_leaves OR 2^max_depth > num_leaves. (num_leaves=31).
[LightGBM] [Warning] Accuracy may be bad since you didn't explicitly set num_leaves OR 2^max_depth > num_leaves. (num_leaves=31).
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000445 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 1838
[LightGBM] [Info] Number of data points in the train set: 16512, number of used features: 8
[LightGBM] [Info] Start training from score 2.071947
LGBMRegressor
LGBMRegressor(max_depth=6, objective='regression', random_state=42)モデルの評価
LightGBMを使って住宅価格の予測モデルを構築したあとは、そのモデルが「どれくらい正確に予測できているか?」を評価する必要があります。回帰モデルの評価では、主に以下の3つの指標がよく使われます。
- MSE(Mean Squared Error):予測値と実際の値の誤差の2乗の平均。値が小さいほど精度が高いです。
- RMSE(Root Mean Squared Error):MSEの平方根をとったもの。単位が元のデータと揃うので直感的にわかりやすいです。
- R²(決定係数):1に近いほど良い予測ができていることを示します。全体の分散のうち、どれだけモデルで説明できているかを表します。
これらをPythonで計算してみましょう。実際の住宅価格と、モデルによる予測値を比較して、誤差や精度を数値で評価します。
from sklearn.metrics import mean_squared_error, r2_score
import numpy as np
# テストデータに対する予測
y_pred = model.predict(X_test)
# 各種評価指標を計算
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
# 結果の表示
print(f"MSE: {mse:.4f}")
print(f"RMSE: {rmse:.4f}")
print(f"R²: {r2:.4f}")
コード解説
from sklearn.metrics import mean_squared_error, r2_score
回帰モデルの評価に使う指標(MSEとR²)をscikit-learnからインポートしています。import numpy as np
RMSEを求めるために平方根を計算するライブラリNumPyを使います。y_pred = model.predict(X_test)
学習済みのモデルにテストデータを入力して、予測値を出しています。mean_squared_error(y_test, y_pred)
実際の値と予測値の誤差の2乗の平均(MSE)を計算しています。np.sqrt(mse)
MSEに平方根をかけてRMSEを算出しています。単位をそろえるために大切です。r2_score(y_test, y_pred)
モデルがどれだけ全体の傾向を捉えられているか(R²)を評価しています。print(f"...")
小数点以下4桁まで結果を見やすく出力しています。
結果はこんな感じです
MSE: 0.2246
RMSE: 0.4739
R²: 0.8286これらの数値から読み取れるポイントを解説していきます。
まず、MSE(平均二乗誤差)が 0.2246 という値は、「住宅価格の予測値と実際の値との二乗誤差の平均」が約 0.22 であることを示しています。MSEは誤差が大きいほど急激に値が大きくなるので、これが小さいということは、大きく外した予測が少ないということになります。
次に、RMSE(平方根平均二乗誤差)が 0.4739 です。これは、モデルの予測が実際の住宅価格と平均して約 0.47 単位(単位はこのデータでは、10万ドル単位)ズレていることを意味します。つまり、「住宅価格を予測すると、おおよそ4万7千ドル前後の誤差が出てるよ」という感覚で受け取れます。まあまあ良い精度ですね!
最後に、R²(決定係数)が 0.8286 というのは、全体の価格変動のうち約 83% をこのモデルで説明できているということを意味しています。1に近いほど精度が良いので、0.8286 はかなり高い方です。単純な線形回帰ではなかなかここまで出ないので、LightGBMの力が出てますね!
総合的に見て、「このモデルはかなり良い精度でカリフォルニア州の住宅価格を予測できている」と言える結果です。
特徴量の重要度とツリーを見てみよう
モデルの評価が終わったら、「このモデルは何を根拠に予測しているのか?」を確認するのも大事なステップです。特にLightGBMのような決定木ベースのモデルでは、「どの特徴量(列)がどれだけ重要だったか」を数値やグラフで簡単に確認できます。
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Hiragino sans' # 日本語フォント設定
# 特徴量の重要度を取得して可視化
lgb.plot_importance(model, max_num_features=10, importance_type='gain')
plt.title("特徴量の重要度")
plt.tight_layout()
plt.savefig('feature_importance_by_lgbm.webp', format='webp')
plt.show()
コード解説
plt.rcParams['font.family'] = 'Hiragino sans'
mac用に日本語フォントを設定。windowsの場合は'Meiryo'などを設定import matplotlib.pyplot as plt
グラフを表示するためにmatplotlibを使います。lgb.plot_importance(model, ...)
学習済みモデルから、特徴量の重要度を自動で棒グラフにしてくれる便利な関数です。max_num_features=10
上位10個の特徴量を表示します。数を変えればもっと見せることもできます。importance_type='gain'
「どれだけ予測誤差を減らすのに貢献したか」という視点で重要度を出します。他に ‘split’ もありますが、gain のほうが実務的にわかりやすいです。plt.title(...),plt.tight_layout(),plt.show()
グラフにタイトルを付けたり、表示レイアウトを整えて、最後に画面に表示しています。
それでは、まず特徴量の重要度を見てみましょう。
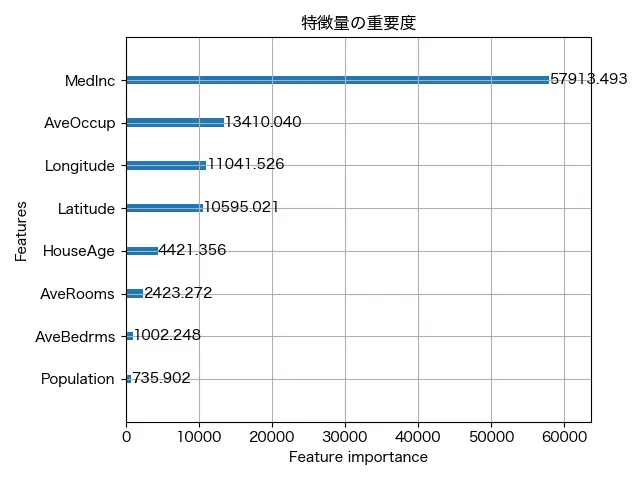
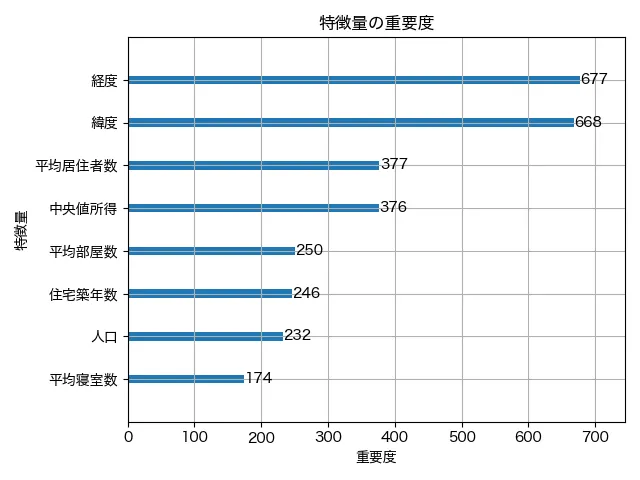
まず、最も重要なのは MedInc(中間所得)です。重要度は約57,913と、他の変数と比べても圧倒的に高くなっています。つまり、モデルは「その地域の中間所得が住宅価格に一番影響している」と判断しているということです。これは直感的にも納得できますね。所得が高い地域ほど、住宅価格も高くなりやすい傾向があるからです。
次に効いているのは Longitude(経度:重要度 11,041)と Latitude(緯度:10,595)です。これらは地域情報であり、つまりモデルは「どのあたりの地域か」をかなり重視していることがわかります。カリフォルニア州は地域によって住宅価格の差が大きいため、この結果も納得です。
その次に重要なのが AveOccup(平均居住人数:13,410)です。これも意外と高い数値になっていて、「1住宅あたりに何人住んでいるか」も価格に影響を与えていることが読み取れます。これは、人口密度のような意味合いもあると考えられますね。
HouseAge(築年数:4,421)や AveRooms(平均部屋数:2,423)も一定の影響を持っていますが、やや控えめな印象です。AveBedrms(平均寝室数)と Population(人口)は重要度が低めで、モデルにとっては「判断材料としてあまり使っていない」ようです。
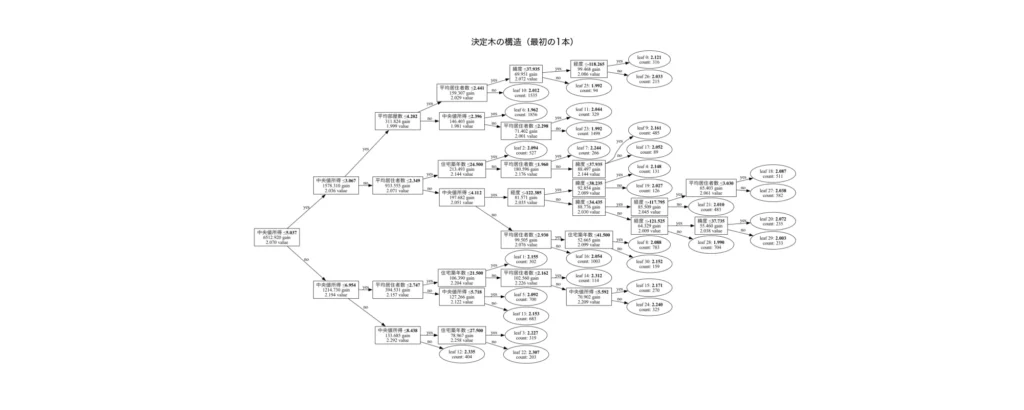
また、LightGBMはたくさんの決定木を組み合わせて予測を行う「アンサンブル学習」のモデルです。そのため、1本1本の木はシンプルでも、全体ではとても複雑な判断ができるようになっています。ここでは参考として、「実際にLightGBMが構築した木の1本」を可視化してみます。これを見ることで、モデルがどの特徴量を使って、どんな条件で分岐して、最終的な予測にたどり着いているのかを目で見て確認することができます。
import matplotlib.pyplot as plt
# Tree 0 を表示(1本目の木)
lgb.plot_tree(model, tree_index=0, figsize=(20, 10), show_info=['split_gain', 'internal_value', 'leaf_count'])
plt.title("LightGBM - Decision Tree (Tree 0)")
plt.show()
結果はこんな感じです。
まあ、正直、多くの木の連結でモデルを作っているので、一つだけ見て何か解釈できるのかというと、難しいですね(汗)
LightGBMのパラメータ設定の考え方
LightGBMは非常に高性能な機械学習モデルですが、その性能を引き出すにはパラメータの調整(チューニング)がとても重要です。パラメータの設定によって、精度が上がったり、過学習を防げたり、学習時間が速くなったりと、大きく挙動が変わります。
ここでは、LightGBMの代表的なパラメータについて、公式サイトを参考に、解説していきます!
パラメータの設定方法
例として、次で説明する「高精度を目指すなら」で紹介したパラメータの設定を紹介します。
model = lgb.LGBMRegressor(
objective='regression', # 回帰問題
boosting_type='gbdt', # 勾配ブースティング
n_estimators=1000, # 多めに木を作る(学習率が小さいため)
learning_rate=0.01, # 小さな学習率で精度を追求
max_depth=8, # 木の深さをある程度制限
num_leaves=128, # 複雑なモデルを許容(ただしデータ量に注意)
min_child_samples=20, # min_data_in_leaf:葉に必要な最小サンプル数
min_child_weight=1e-3, # min_sum_hessian_in_leaf:最小ヘッセ値合計
subsample=1.0, # bagging_fraction:100%のデータを使用
subsample_freq=0, # bagging_freq:バギングなし
colsample_bytree=1.0, # feature_fraction:全特徴量を使用
reg_alpha=0.0, # lambda_l1:L1正則化なし(必要に応じて増やす)
reg_lambda=0.1, # lambda_l2:軽めのL2正則化
max_bin=511, # 特徴量ビンの分割数を増やして精度向上
random_state=42 # 再現性確保
)LGBMRegressorの場合は、上記のように、パラメータをどんどん追記していくイメージです。
それでは、公式サイトを参考にしながら用途別にパラメータの設定方法について解説してみましょう。
高精度を目指すなら
- max_bin(デフォルト:255)
値を大きくすることで特徴量の分解能が上がり、精度が向上することがある。ただし、学習時間とメモリ使用量が増える。例:512など。 - learning_rate(デフォルト:0.1) + num_iterations(デフォルト:100)
learning_rateを小さく(例:0.01)するとモデルの学習が安定するが、num_iterationsを増やす必要がある(例:1000以上)。バランスが重要。 - num_leaves(デフォルト:31)
値を大きくするとモデルの表現力が増すが、過学習のリスクも上がる。例:50、100など。ただし、データ量が少ないときは控えめにする。 - dart(boosting_type)
ドロップアウト付きの勾配ブースティング。過学習を抑えつつ高精度が狙える。精度重視のケースでは有効。 - 学習データを増やす
特に精度を上げたい場合は、より多くの質の高いデータを用意することが基本かつ効果的。
過学習を防ぐには
- max_bin:小さく(例:63)
特徴量の分解能を落として過学習を抑える。 - num_leaves:小さく(例:15〜31)
モデルの複雑さを抑える。 - min_data_in_leaf(デフォルト:20)
葉に含まれる最小データ数。値を大きく(例:100〜1000)することで、葉が少数データを過学習するのを防ぐ。 - min_sum_hessian_in_leaf(デフォルト:1e-3)
勾配の2次微分の合計。値を大きく(例:1.0)することで、情報量の少ない分割を抑制。 - bagging_fraction(デフォルト:1.0)+ bagging_freq(デフォルト:0)
例:bagging_fraction=0.8、bagging_freq=5にすると、5イテレーションごとに80%のデータをサンプリング。過学習防止に有効。 - feature_fraction(デフォルト:1.0)
各ツリーごとに使う特徴量をランダムに選ぶ。例:feature_fraction=0.8で80%の特徴量を使用。 - lambda_l1、lambda_l2(デフォルト:0.0)
L1・L2正則化。例:lambda_l2=1.0で係数の過大を抑える。 - min_gain_to_split(デフォルト:0.0)
分割時の最小ゲイン。小さな分割を抑えて過学習を防ぐ。例:min_gain_to_split=0.1 - max_depth(デフォルト:-1)
ツリーの深さに上限を設ける。例:max_depth=7 - extra_trees(デフォルト:false)
分割点をランダムに選び、汎化性能を高めることがある。 - path_smooth(デフォルト:0)
パスごとの勾配の急激な変化を抑える。
学習時間を短縮するには
ハードウェアの活用
- num_threads(デフォルト:自動)
使用するCPUスレッド数。実行環境に合わせて設定(例:8コアならnum_threads=8)。 - GPU版 LightGBM
学習が非常に高速になる場合がある。インストール時に--gpuを指定。 - 分散学習
データが大規模な場合はマシンを複数用いることで学習時間を短縮可能。
木を浅くする
- max_depth、num_leaves
小さく設定(例:max_depth=6、num_leaves=31)することで木の構造が単純になり学習が速くなる。 - min_gain_to_split、min_data_in_leaf、min_sum_hessian_in_leaf
これらを大きく設定すると、細かい分割が抑制され、学習速度が向上する。
木の本数を減らす
- num_iterations(デフォルト:100)
学習ラウンド数。例:num_iterations=50に減らすと学習が速くなるが、精度は落ちる場合も。 - learning_rate
num_iterationsを減らすなら、逆にlearning_rateを上げる(例:0.3)必要あり。 - early_stopping_round(デフォルト:0)
バリデーション精度が改善しないラウンド数。例:early_stopping_round=10
スプリットの計算を減らす
- feature_pre_filter(デフォルト:True)
有効な特徴量のみ事前にフィルタリング。学習速度が向上。 - max_bin(例:63〜127)
特徴量のビニング数を減らすことで、スプリット数が減少し高速化。 - min_data_in_bin(デフォルト:3)
小さいビンをスキップすることで無駄な分割処理を減らせる。 - feature_fraction(例:0.5〜0.8)
一部の特徴量だけを使うことでスプリット数が減り高速化。 - max_cat_threshold(デフォルト:32)
カテゴリ変数の分割候補数を制限。例:max_cat_threshold=8
データ量を減らす
- bagging_fraction、bagging_freq
前述のように、部分データのみ使って学習回数を増やすことで高速化。 - save_binary(CLIのみ)
save_binary=Trueにすると、学習用データをバイナリ形式で保存し、次回の読み込み・前処理を高速化できる。
まとめ
以上、lightgbmについての解説でした。ちょっと長くなりましたが、どれも実務で使う上でとても重要な点です。とくに、パラメータの設定は他のモデルに比べ繊細で、細かく設定する必要があります。今回のケース別の設定方法などを参考に、ぜひ、あなた自身の最適なモデルを構築してみてください!