こんにちは、デジタルボーイです。普段はクライアントのAI開発、データ分析、中小企業コンサルを仕事としています。今回は、物体検知で最も広く使われているYOLOシリーズについて、バージョンの違いと選び方を現場実装の視点から解説します。

デジタルボーイです。
データサイエンス歴20年以上のおっさんです(元SAS institute japan データサイエンティスト)。中小企業診断士として、AI開発、データサイエンス、WEBマーケティング、SEOに関するデータ分析、コンサルティング、補助金支援の仕事をしています。自己紹介の詳細はコチラ
はじめに ― 「最新モデルが常に正解」ではない理由
YOLOは進化が速く、2026年現在ではYOLO26が最新モデルとしてリリースされています。こう書くと「じゃあ最新のYOLO26を使えばいいんでしょ?」と思うかもしれません。しかし、現場の実装はそう単純ではありません。
そもそも、クライアントから「最新モデルを使ってほしい」とバージョンを指定されることはまずありません。モデルの違いを把握しているのは開発者側であり、クライアントの課題に対してどのモデルが最適かを判断し、責任を持って選定するのはAI開発者の仕事です。
僕は仕事柄、最新モデルには常に目を通すようにしていますが、最新が常に最適とは限らないというのが正直な実感です。たとえば、最新モデルは精度が高い一方で、モデルが重い(使用するメモリが大きい)ことがある。論文やベンチマーク上では素晴らしい数値を出していても、中小企業の現場にあるような一般的なスペックのPCでは、処理速度が出ないことは珍しくありません。
つまり、モデル選定とは精度と重さのトレードオフを見極めることであり、「最新だから最高」という単純な話ではないんですよね。
本記事では、Ultralytics公式のYOLOシリーズ(YOLOv8 → YOLO11 → YOLO26)を中心に、各バージョンの特性を比較し、現場のどんな条件にどのモデルが合うのかを、AIエンジニア兼中小企業診断士の視点から解説します!
YOLOの系譜を整理する ― 公式版とコミュニティ版の違い
そもそもバージョンが多すぎる問題
YOLOに興味を持って検索すると、v5、v7、v8、v10、v11、v12、v13、そしてYOLO26……と、大量のバージョンが出てきて混乱するはずです。一般の開発者でもキャッチアップが追いつかない状況なので、非エンジニアのクライアントがバージョンの違いを理解しているケースはまずありません。ここを整理するのが、まず最初に必要なことです。
Ultralytics公式版とコミュニティ版
YOLOの世界には、大きく分けて2つの流れがあります。
① Ultralytics公式版: YOLOv5 → YOLOv8 → YOLO11 → YOLO26 Ultralyticsという企業が一貫して開発・メンテナンスしている公式系列です。商用利用実績も豊富で、ドキュメントやサポートが充実しています。現場実装で最も安定して使えるのはこの系列です。
② コミュニティ・研究者版: YOLOv6、v7、v9、v10、v12、v13 など 大学の研究者やコミュニティが独自に開発したバリアントです。論文上では高い性能を示すものもありますが、商用での利用実績やサポート体制はUltralytics公式と比べると限定的です。特にYOLOv12やv13はアテンション機構など新しい技術を取り入れていますが、NMS(後処理)への依存やエッジデバイスでの動作に課題が残っています。
番号が11から26に飛んでいる理由
YOLO11の次がYOLO26というのは、番号が飛びすぎに見えるかもしれません。これはUltralyticsが、コミュニティ版のバージョン番号(v12、v13…)との混同を避けるために、あえて大きく番号を飛ばしたためです。つまり、YOLO26はv12やv13の「次」ではなく、Ultralytics公式版としてYOLO11の正統な後継にあたります。
実務で重要なのは「使えるかどうか」
AIエンジニア的な話をすると、ベンチマーク上の精度だけを見れば、コミュニティ版の中にも優秀なモデルはあります。ただし、現場で実際に使うとなると話は別です。
たとえばYOLOv8は、それ以前のバージョンから精度が大幅に向上した転換点となったモデルで、多くの開発者に広く認知されています。その後のYOLO11、そして最新のYOLO26はこの流れを受けて、精度だけでなくエッジデバイスでの動作効率を大幅に改善しています。
一方で、オリジナルの学習済みモデルでは精度が良いのに、自社のデータでカスタム学習をさせるとチューニングが難しく精度がうまく出ないモデルも存在します。論文上のベンチマーク結果と、実際のカスタム学習での使い勝手は別物です。
この「論文上の性能」と「現場での使い勝手」の乖離こそが、モデル選定で最も注意すべきポイントであり、開発者が責任を持って検証すべき部分です。
比較表:精度・速度・用途で見るYOLOバージョン別の特性
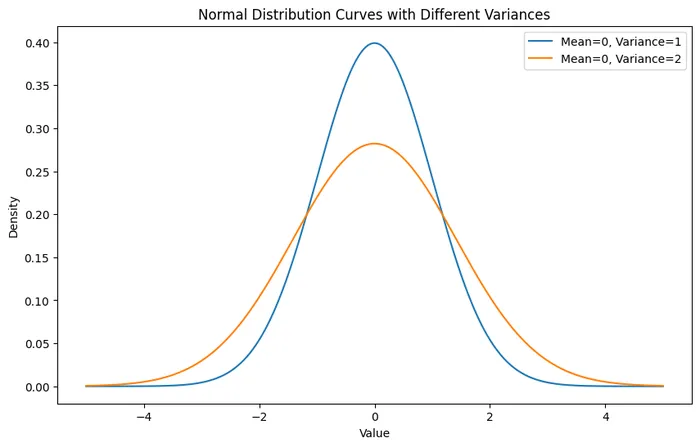
Ultralytics公式モデルの比較(Nanoサイズ基準)
まず、現場実装で最もよく使われるNano(軽量)サイズで、Ultralytics公式の3モデルを比較します。数値はCOCOデータセットでのベンチマークです。
| 項目 | YOLOv8n | YOLO11n | YOLO26n |
|---|---|---|---|
| リリース年 | 2023年 | 2024年 | 2025年(公開2026年1月) |
| 精度(mAP50-95) | 37.3 | 39.5 | 40.9 |
| CPU推論速度 | 約80ms | 約56ms | 約39ms |
| GPU推論速度(T4 TensorRT) | 約1.0ms | 約1.5ms | 約1.7ms |
| NMS(後処理) | 必要 | 必要 | 不要(ネイティブE2E) |
| DFL | あり | あり | 除去 |
| 小物体検知 | 標準 | 改善 | 大幅改善(STAL) |
| エッジデバイス最適化 | △ | ○ | ◎ |
| 商用利用実績 | 非常に豊富 | 豊富 | 拡大中 |
| カスタム学習の安定性 | 非常に安定 | 安定 | おおむね安定(一部タスクで要調整) |
※数値はUltralytics公式モデル比較ページおよび論文(Sapkota et al., 2025)に基づく。YOLOモデルはONNX、TensorRT、OpenVINOなど多様なフォーマットへのエクスポートに対応しており、デプロイ先に応じた最適化が可能
コミュニティ版(v12/v13)との違い
参考として、コミュニティ版のYOLOv12/v13についても触れておきます。
| 項目 | YOLOv12 | YOLOv13 |
|---|---|---|
| 開発元 | コミュニティ(非Ultralytics) | コミュニティ(非Ultralytics) |
| 特徴 | アテンション機構ベース | 改良型フュージョン |
| NMS | 必要 | 必要 |
| 商用利用実績 | 限定的 | 限定的 |
| 注意点 | メモリ消費大・CPU推論が遅い | YOLO11との精度差が小さい割に大型 |
Ultralytics公式も、現時点ではYOLOv12/v13の本番利用は推奨していません。
比較表の読み方 ― 数字だけで選んではいけない
ここからが大事な話です。上の表だけ見ると「YOLO26が全部上じゃないか」と思うかもしれません。精度は最高、CPU速度は最速、NMSも不要。じゃあYOLO26一択でしょ、と。
AIエンジニア的には、話はそう単純ではありません。
まず、ベンチマークの精度はCOCOデータセット(汎用的な画像データセット)での値です。実際の現場で自社のデータを使ってカスタム学習をさせたとき、同じ数字が出るとは限りません。特にYOLO26は新しいモデルである分、一部のタスク(OBBなど)ではカスタム学習時にチューニングが難しいケースが報告されています。
一方、YOLOv8は3年以上の商用利用実績があり、カスタム学習の安定性は非常に高い。「枯れた技術」の安心感があります。
もう一つ重要なのは、比較表にない評価軸です。回答にも書いたように、正式リリースか開発中か、商用実績があるか、そしてカスタム学習をしたときにチューニングが素直にいくかどうか。これらは論文のベンチマークには載っていませんが、現場で使う上では精度や速度と同じくらい重要です。
現場実装の視点①:エッジAIか、クラウドAIか
判定速度がシビアかどうかで決まる
物体検知を現場に実装するとき、まず判断しなければならないのが「エッジAI(現場のPCやデバイスで処理を完結させる)」か「クラウドAI(Cloud Run等のクラウドサービスで処理する)」かという選択です。
僕の場合、この判断基準はシンプルで、判定速度がシビアかどうかで決めています。
エッジAIを選ぶケース: 製造ラインで製品がどんどん流れてきてリアルタイムに判定しないといけない場合。あるいは、車やロボット、装置が移動しながら判定を続ける必要があるケース。こうした場面では、クラウドとの通信にかかるわずかな遅延すら許容できないことがあります。

クラウドAIを選ぶケース: 判定速度にそれほどシビアでない場合。たとえば、撮影した画像をまとめて解析する、あるいは数秒の遅延が許容される検品作業など。ただし、クラウド経由では画面がカクカクする(フレー

ムレートが下がる)点は、事前にクライアントに理解してもらう必要があります。
エッジAIの実装構成 ― 大がかりな設備は不要
エッジAIと聞くと、専用のハードウェアや高価なデバイスが必要だと思われがちですが、僕が実装する構成はもっとシンプルです。
基本構成:
- PC: 通常のデスクトップPCにGPUを搭載したもの。特殊な産業用PCではなく、一般的なものでOK
- カメラ: USBで接続するオンラインカメラが基本。天井配線が必要な場合はPoE/GigEカメラを使うこともある
当社はハードウェア開発をしない、小規模なAI導入を専門としています。大がかりな専用装置ではなく、汎用的なPC+カメラで構築するので、初期コストを抑えられます。
Jetson Orinについて: NVIDIAのJetson Orinは、エッジAI専用の小型デバイスとしてよく名前が挙がります。YOLO26もJetson Orin上での動作が公式にサポートされており、消費電力が低く設置スペースも小さいため、たとえば工場内の狭いスペースに設置する必要がある場合や、屋外の移動体(AGVやドローン)に搭載するケースでは有力な選択肢です。ただ、僕の場合はデスクトップPC+GPUの構成で十分なケースがほとんどなので、Jetsonはあくまで「必要に応じて」という位置づけです。

クラウドAI(Cloud Run)のメリットと使いどころ
一方で、僕がクライアントに積極的にすすめるのがクラウドAI、特にGoogle Cloud Runでの実装です。
最大のメリットは、スマホやタブレットだけで動くこと。 PC側にGPUを積む必要がなく、ブラウザからアクセスするだけで物体検知が使えます。初期の設備投資がほぼゼロで、メンテナンスも圧倒的に楽です。
特にPoC(お試し開発)の段階では、クラウド実装で十分なケースが大半です。開発中にクライアントがリアルタイムでプロトタイプを触りたいというニーズは必ずあるので、そのためにもクラウドでの実装は欠かせません。
PoCでクラウド実装を試してみて、速度的に問題がなければそのまま本番もクラウドで運用する。もし速度がシビアで難しそうなら、そこで初めて産業用PCにGPUを搭載したエッジ構成に切り替えを検討する——この段階的なアプローチが、中小企業にとっては最もリスクが低い進め方です。
YOLO26はどちらの構成でも有利
ここでセクション3の比較表の話に戻ります。YOLO26はCPU推論速度がYOLOv8比で最大43%高速化されており、NMSの後処理も不要です。これはエッジ・クラウドどちらの構成でも恩恵があります。
エッジであれば、同じGPUでもより高いフレームレートで処理できる。クラウドであれば、サーバー側の処理負荷が軽くなる分、コストを抑えられる。モデル選定の観点からも、YOLO26のエッジ最適化設計は現場実装と相性が良いと言えますね!
現場実装の視点②:精度と速度のトレードオフをどう判断するか
「速度優先」と「精度優先」は現場の要件で決まる
YOLOのモデル選定で最も悩ましいのが、精度と速度のトレードオフです。比較表で見たように、モデルのサイズを大きくすれば精度は上がるが処理は重くなる。小さくすれば速いが精度は下がる。では、どちらを優先すべきか。
答えは「現場による」としか言いようがないのですが、僕が実際に経験したケースで説明します。
速度を優先したケース ― 果物の出荷ライン
完全自動化を目指さず、かつ大量に処理する必要があるケースでは、速度を優先させます。
以前対応したりんごやなしの出荷作業がまさにこれでした。ベルトコンベア上をりんごがどんどん通過していくので、一つひとつをじっくり判定している余裕がありません。この場合はスピードを最優先にしつつ、複数台のカメラ(AI)で同時に検知することで、精度を「数」でカバーしました。

1台のカメラで高精度を追求するのではなく、複数台で分担して検知する。1台が見落としても別のカメラが拾える。この「速度×台数」で品質を担保するアプローチは、大量処理の現場では非常に有効です。
精度を優先したケース ― 半導体工場の工具管理
逆に、速度はまったく求めず精度を最優先にするケースもあります。
ある半導体部品の納品工場では、作業に使った工具を一つ残らず元の場所に戻す必要がありました。工具の置き忘れが発覚すると、親会社から出荷停止になる。つまり、見落としのリスクが極めて大きいケースです。

この場合、スピードは極論まったく必要ありません。就業時間までに工具が全て揃っているかを確認できればいい。なので、処理が重くても精度の高いモデルを使い、時間をかけてでも確実に検知することを優先しました。
誤検知と見落とし ― どちらを嫌がるかもケースバイケース
精度と速度のトレードオフと密接に関連するのが、誤検知(良品をNGと判定)と見落とし(不良品を見逃す)のどちらを許容するかという問題です。
これもケースバイケースですが、傾向はあります。
見落としを極力減らすべきケース: 半導体関連、自動車部品関連、受注生産品など、一品あたりの単価が高い製品。見落としによる不良流出は、元請けからのクレームや出荷停止に直結するため、誤検知(良品を弾いてしまう)はある程度許容してでも、見落としをゼロに近づける方向で調整します。
誤検知を減らすべきケース: ネジ、印刷物など、単価が低く大量に生産する製品。あるいは完全自動化せず、人がAIの判定結果を確認する運用の場合。誤検知が多いとそのたびに人が確認する手間が増え、結果としてAI導入の効果が薄れてしまうためです。
モデル選定への落とし込み
この「速度か精度か」「誤検知か見落としか」の判断が、モデル選定に直結します。
速度優先であれば、YOLO26のNano(n)やSmall(s)サイズが候補になります。YOLO26はNMSが不要な分、同じサイズでも旧モデルよりレイテンシが安定するという利点があります。
精度優先であれば、YOLO26のMedium(m)以上、あるいは実績の豊富なYOLOv8のLarge(l)サイズも選択肢に入ります。カスタム学習の安定性を重視するなら、YOLOv8の方が安心感があるケースもあります。
結局のところ、モデルを先に決めるのではなく、現場の要件を先に定義するのが正しい順序です。どんな対象を、どんな速度で、どこまでの精度で検知する必要があるのか。それが決まれば、最適なモデルとサイズは自ずと絞られます。
現場実装の視点③:「なぜ不良と判定したのか」を説明できるか
製造現場では「AIが言ったから」では通らない
物体検知の精度や速度と並んで、現場で意外と重要になるのが**「AIの判定根拠を説明できるか」**という問題です。
特に製造業のクライアントからは、「AIがこの製品を不良と判定したけど、なぜ不良なのか」という質問が出ることがあります。品質管理の現場では、不良判定には理由が必要です。元請けや品質監査の場で「AIがそう判断しました」だけでは説明責任を果たせません。
この傾向は、単価の高い製品や安全性に関わる部品を扱う現場ほど強くなります。自動車部品、医療機器関連、半導体関連などでは、「なぜこの製品がNGなのか」をトレーサビリティの一環として記録・報告する必要があるケースもあります。
Heatmap(ヒートマップ)による判定根拠の可視化
こうした要求に応えるために使われるのが、Grad-CAMなどの手法によるHeatmap(ヒートマップ)の可視化です。簡単に言えば、AIが画像のどの部分に注目して判定を行ったかを、色の濃淡で視覚的に表示する技術です。
たとえば、金属パーツの外観検査で「キズあり」と判定された場合、Heatmapを見ると、AIがパーツ表面の特定の箇所を赤く(=強く注目して)表示しています。これにより、「AIはここのキズを検知してNGと判断した」ということが、技術者でなくても目で見て理解できます。
実際にクライアントにHeatmapを見せると、「なるほど、AIはここを見ているのか」と納得される方がほとんどです。逆に、Heatmapを見ることで「AIが想定外の箇所を見て判定している」ことに気づくケースもあります。たとえば、製品のキズではなく背景の汚れに反応していた場合、それは学習データの問題です。こうした発見がAIの精度改善にもつながるので、Heatmapは説明責任のためだけでなく、開発プロセスの一部としても有用です。
たとえば、下は僕の愛犬の写真ですが、この画像にEigenCAMを適用すると、耳のあたりが赤く表示されます。これはAIが「この物体は犬である」と判定する際に、耳の形状を重要な手がかりとして使っていることを意味しています。犬種ごとに耳の形は大きく異なるため、AIにとっては物体を識別する上で非常に特徴的なパーツなんですよね。

これを製造現場に置き換えると、たとえば金属パーツの外観検査で「キズあり」と判定された場合、Heatmapではそのキズの箇所が赤く表示されます。「AIがどこを見てNGと判断したのか」が一目でわかるわけです。
逆に、もし製品ではなく背景が赤くなっていたら要注意です。それはAIが製品の不良ではなく、背景の汚れや照明の変化に反応している可能性を示しています。
YOLOのモデルごとの可視化のしやすさ
AIエンジニア的な補足をすると、YOLOモデルはすべてHeatmapの生成に対応できますが、モデルの構造によって可視化の相性に差はあります。
YOLOv8やYOLO11はCNNベースの構造がシンプルなため、Grad-CAMとの組み合わせが素直に動きます。YOLO26もCNNベースの構造を維持しているので、同様にHeatmapの生成は問題ありません。一方、コミュニティ版のYOLOv12のようにアテンション機構を多用するモデルは、可視化の解釈がやや複雑になる傾向があります。
モデル選定の際、可視化のしやすさを最優先にする必要はありませんが、判定根拠の説明が求められる現場では、検討材料の一つとして頭に入れておくべきです。
Heatmapは、AIが「ここに物体がある」と検知した位置を色で表したものです。この画像では犬の鼻あたりが緑色に表示されていますが、これはAIが犬の顔を検知し、その検知枠の中心がちょうど鼻付近にあることを示しています。先ほどのEigenCAMが「AIがどこを見て犬だと判断したか(=耳)」を示すのに対し、Heatmapは「どこに犬がいるか(=位置)」を示す——つまり、判定の根拠と検知の結果という、異なる情報を可視化しています。製造現場であれば、EigenCAMで「AIが製品のどこのキズを見てNGと判断したか」を確認し、Heatmapで「ライン上のどの位置で不良が多く発生しているか」を把握する、といった使い分けが可能です。
モデル選定のフローチャート ― 自社に合ったYOLOの選び方
そもそもAIが最適解とは限らない
モデル選定の話をする前に、一つ大事なことを書いておきます。
僕はクライアントからAI導入の相談を受けたとき、いきなりモデルの話には入りません。まず最初にやるのは業務改善計画を立てることです。工程を洗い出して、ボトルネックを特定する。そのボトルネックの解決策として、AIが最適なのか、IT化(システム導入)で十分なのか、あるいは単なる見える化(ホワイトボードやエクセル表)で解決できるのかを判断します。
さらに、それをやった場合にどれくらいのコスト削減になるのか、導入に対するROI(投資対効果)はいくらかを算出します。中小企業診断士的に言えば、AIはあくまで課題解決の手段の一つであって、目的ではありません。
この前提を踏まえたうえで、「AIによる物体検知が最適」と判断した場合のモデル選定フローを紹介します。
実務的なモデル選定フロー
僕が実際にやっているモデル選定の流れを、フローチャート形式で整理します。
① まず最新モデル(YOLO26)を試す
↓
② サイズを選定する
├─ クラウド実装(Cloud Run) → 小さめ(Nano / Small)
└─ エッジ実装(GPU搭載PC) → 要件に応じて(Small〜Large)
↓
③ 自社データでカスタム学習(PoC)
├─ 精度が出た → そのまま本開発へ
└─ 精度が出ない / 学習が安定しない
↓
④ 別モデル・別サイズで再検証
├─ YOLOv8(安定性重視)
└─ YOLO11(バランス重視)
↓
⑤ 最適な組み合わせを確定 → 本開発へ各ステップの補足
① 最新モデルから試す理由: 基本的に最新モデルが最も性能が高いので、まずはYOLO26を起点にします。最初から古いモデルを選ぶ理由はありません。
② サイズ選定の考え方: YOLOにはNano(n)、Small(s)、Medium(m)、Large(l)、Extra Large(x)のサイズバリエーションがあります。クラウド実装の場合はサーバーコストを抑えるために小さめのモデルを使うのが基本。エッジ実装の場合は、GPUのスペックと求められる速度・精度のバランスで選びます。
③ PoCでの検証が最重要: ベンチマークの数値がどれだけ良くても、自社データでカスタム学習をしたときに精度が出なければ意味がありません。ここが最も大事なステップです。だいたい500枚程度の画像を用意し、実際に学習させて精度を確認します。
④ うまくいかない場合の切り替え: YOLO26でカスタム学習がうまくいかない場合は、YOLOv8やYOLO11に切り替えて試します。特にYOLOv8はカスタム学習の安定性が非常に高いので、「最新モデルで精度が出ない」ときの有力な代替候補です。ここでも、バージョンの新しさよりも実際に精度が出るかどうかで判断します。
「最新がダメなら古いモデル」は恥ずかしいことではない
このフローを見てわかるように、僕の選定方針は「まず最新を試して、ダメなら切り替える」です。最新モデルに固執する必要もなければ、古いモデルを使うことが技術力の低さを意味するわけでもありません。
現場で動くこと、精度が出ること、クライアントの課題が解決すること。それが全てです。モデルの新しさは手段であって目的ではない。この考え方は、AIエンジニアとしても、中小企業診断士としても、僕が一貫して大事にしているスタンスです。
まとめ ― 福岡・山口の製造現場に即したAI開発のご相談
ご相談・無料お見積もり
まずは無料コンサルティングをお気軽にお申し込みください。ZoomによるWEB会議もしくはお電話にて45分程度の無料コンサルティングを実施します。
福岡県、山口県のお客様には地域の課題や状況に特化した迅速かつ柔軟なAI開発をご提案します。