こんにちは、デジタルボーイです。今回は決定木による分類問題をPythonとscikit-learnを使って構築したいと思います!個人的には、データ分析コンサルで分類問題をする際、初手「決定木!!」というケースが多々あります。というのも、後から出ますが、決定木のアウトプットはあみだくじのようなツリー状のアウトプットが出て、それが、僕のクライアント企業や中小企業の社長は大好きなんです。
他の、分類モデルと違って、圧倒的にわかりやすく直感的な点は決定木の持つ、他にはない魅力だと思います。なので、データ分析コンサル的にはなくてはならない手法だと思っています!

デジタルボーイです。
データサイエンス歴20年以上のおっさんです。中小企業診断士として、データサイエンス、WEBマーケティング、SEOに関するデータ分析、コンサルティングの仕事をしています。自己紹介の詳細はコチラ
決定木とは?
決定木(Decision Tree)は、データを分岐させながら分類や予測を行うシンプルで直感的な機械学習アルゴリズムです。とはいえ、おそらく決定木を使うシーンは回帰予測(連続的な数値を予測)でなく分類(主に2値)なのではないでしょうか?
決定木はツリー状の構造を持ち、各分岐(ノード)でデータを分割しながら、最終的な予測(葉ノード)に到達します。決定木の最大の特徴は、結果が一目瞭然!直感的に理解しやすい!というところです!実際に決定木で出力されるツリー図を見てみましょう。
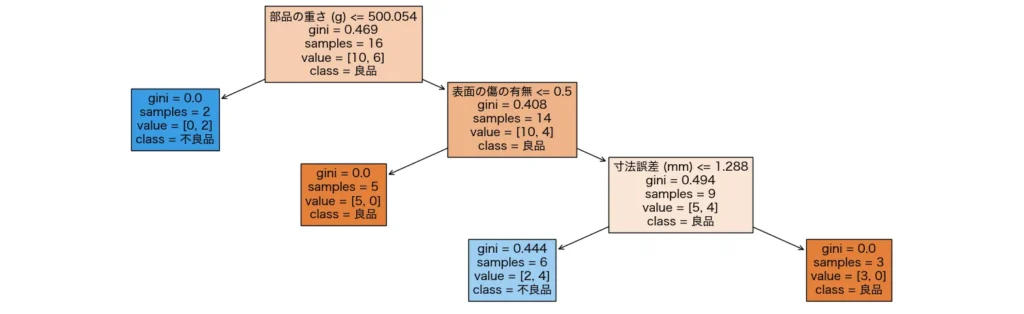
これは、工業部品のロットが<不良/正常か>予測するためのモデルです。例えば、一番上の分岐である「500.054g」以下(左)であれば不良品となる確率が高く、高ければ良品である確率が高い。次の分岐では、「表面の傷」がなければ良品、そうでなければ不良が多い(この場合表面の傷があるデータを1、そうでなければ0としているので)・・・というモデルです。まるであみだくじのようですね!このようなルールの連鎖で<良品と不良品>をふるいにかけていくのが決定木です。
決定木の応用場面
決定木は様々な分野で活用されています。
1. 顧客の購買予測
ECサイトでは、ユーザーの行動データを元に「この人は次にどんな商品を買いそうか?」を予測するのに使われます。例えば「過去にスマホを買った人はイヤホンも買う確率が高い」といったパターンを発見できます。
2. 医療診断
病院では、患者の症状データから病気の診断を行う際に決定木が役立ちます。例えば、「発熱があるか?」「咳が出ているか?」という分岐を通して、風邪なのかインフルエンザなのかを判断できます。
3. 与信審査(ローンの承認)
銀行では、顧客の年収や信用履歴をもとに、ローンを承認するかどうかを決定木で判断することがあります。たとえば「年収が500万円以上か?」「過去に滞納がないか?」といった条件でローン審査が行われます。
4. 異常検知(工場の品質管理)
製造業では、センサーのデータをもとに「この部品は正常か?異常か?」を決定木で分類することができます。製品のサイズや重さ、温度などを基準にして、不良品を検出するのに役立ちます。
決定木の予測精度は、僕の経験的には他の予測モデルに比べてとくに高いわけではない印象です。なので、上記の予測についても、最終モデルというよりは初手としてまずやってみるモデルといった利用方法が多いように思えます。
初手の次に、さらに予測精度を上げたい場合は、決定木の応用モデルでもあるランダムフォレストや勾配ブースティング木を使うことが多いです。
必要なライブラリのインポート
決定木を使うには、scikit-learnライブラリを利用します。まだインストールしていない場合は、以下のコマンドでインストールしてください
pip install scikit-learn numpy matplotlibpipを使ったインストール方法がわからない場合はこちらをご覧ください。



では、必要なライブラリをインポートしましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
これで準備完了です!次に、実際に決定木を使ったモデルの実装を行いましょう。
乳がんデータセットの概要
今回使用するデータセットは、scikit-learn に含まれる 乳がん診断データ(breast cancer dataset) です。これは、腫瘍が良性か悪性かを予測するためのデータ であり、医療分野の機械学習の基本的な例としてよく使われます。
このデータセットには、患者の腫瘍に関する30種類の特徴が含まれており、それらをもとに腫瘍が 「良性(0)」 か 「悪性(1)」 かを分類します。実際の医療現場では、こうしたデータを活用することで、医師の診断を補助するAIモデルが開発されています!
データセットは sklearn.datasets モジュールの load_breast_cancer() を使うことで簡単に取得できます。
from sklearn.datasets import load_breast_cancer
import pandas as pd
# データの読み込み
data = load_breast_cancer()
# データの概要を確認
print(data.DESCR)
コードの解説
load_breast_cancer()を使って、乳がんデータセットを読み込みます。data.DESCRを表示することで、データの詳細な説明を確認できます。
以下のような結果が出力されます。
.. _breast_cancer_dataset:
Breast cancer wisconsin (diagnostic) dataset
--------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
The mean, standard error, and "worst" or largest (mean of the three
worst/largest values) of these features were computed for each image,
...
to diagnose breast cancer from fine-needle aspirates. Cancer Letters 77 (1994)
163-171.
|details-end|
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...このデータセットは、Wisconsin乳がん診断データセット(Breast Cancer Wisconsin – Diagnostic) と呼ばれ、細い針を用いた生検(細胞診) の結果から、腫瘍が 良性か悪性かを判別 するためのものです。
データの基本情報は以下の通りです。
データの基本情報
- データ件数(インスタンス数):569
- 特徴量の数:30(すべて数値データ)
- 目的変数:腫瘍が「良性」か「悪性」かを示すラベル(2クラス)
特徴量についても、以下のような情報が見て取れます。
特徴量の説明
- radius(半径):腫瘍の輪郭の中心から境界線までの平均距離
- texture(テクスチャ):グレースケール画像の標準偏差(濃淡の変動)
- perimeter(周囲長):腫瘍の輪郭の長さ
- area(面積):腫瘍の面積
- smoothness(滑らかさ):半径の局所的な変動
- compactness(コンパクトさ):
(周囲長^2) / 面積 - 1.0の計算値 - concavity(凹みの深さ):腫瘍の輪郭の凹みの程度
- concave points(凹みの数):輪郭上の凹んだ部分の数
- symmetry(対称性):腫瘍の左右対称性
- fractal dimension(フラクタル次元):輪郭の複雑さを示す値(海岸線の長さの概念に近い)
- mean(平均値)
- standard error(標準誤差)
- worst(最大値):腫瘍の3つの最大測定値の平均
データのサンプルを確認
実際のデータの内容を見てみましょう。pandas を使うことで、より分かりやすく表示できます。
# DataFrame に変換
df = pd.DataFrame(data.data, columns=data.feature_names)
# 最初の5行を表示
df.head()コードの解説
pd.DataFrame(data.data, columns=data.feature_names)でデータをpandasのデータフレームに変換します。df.head()でデータの最初の5行を表示し、各特徴量の数値を確認できます。
このコードを実行すると、次のような表が表示されます。
| mean radius | mean texture | mean perimeter | … | worst fractal dimension |
|---|---|---|---|---|
| 17.99 | 10.38 | 122.8 | … | 0.11890 |
| 20.57 | 17.77 | 132.9 | … | 0.08902 |
| 19.69 | 21.25 | 130.0 | … | 0.08758 |
| 11.42 | 20.38 | 77.58 | … | 0.17300 |
| 20.29 | 14.34 | 135.1 | … | 0.07678 |
カラムを全て見たい場合は次のようにコードを書きます。
df.columns結果はこうでした。
Index(['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error', 'fractal dimension error',
'worst radius', 'worst texture', 'worst perimeter', 'worst area',
'worst smoothness', 'worst compactness', 'worst concavity',
'worst concave points', 'worst symmetry', 'worst fractal dimension'],
dtype='object')30件の特徴量の名称を出力できました。
分析の目的とゴール
今回の分析の目的は、乳がん診断データをもとに、腫瘍が良性か悪性かを機械学習で予測することとします。
ゴールは、決定木を用いて乳がんの診断を行い、腫瘍が良性か悪性かを分類するモデルを構築することとします。まずはモデルを実装し、その後に評価指標を計算して性能を確認していきます。
今回の分析を通じて、決定木の理解と利用がすすんでいただければ幸いです!
モデルの実装
まず、データを訓練データとテストデータに分割し、決定木を用いた分類モデルを作成します。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# データの読み込み
X, y = data.data, data.target
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 決定木モデルの作成
clf = DecisionTreeClassifier(max_depth=3, random_state=42)
clf.fit(X_train, y_train)
# 予測(ここでは実行するだけで評価は後で行う)
y_pred = clf.predict(X_test)
コードの解説
train_test_split(X, y, test_size=0.2, random_state=42)- データを 訓練データ(80%) と テストデータ(20%) に分割します。
random_state=42を設定することで、毎回同じ分割結果になるようにします。
DecisionTreeClassifier(max_depth=3, random_state=42)- 決定木のモデル を作成します。
max_depth=3にすることで、木の深さ3つに制限し、過学習を防ぎます。
clf.fit(X_train, y_train)- 訓練データを用いて 決定木モデルを学習 します。
y_pred = clf.predict(X_test)- 学習済みのモデルを使って テストデータの予測 を行います。
- この時点では 評価指標は計算せず、単に予測結果を出すだけ です。
モデルの評価
構築した決定木モデルがどの程度の精度で分類できるのかを評価します。分類モデルの評価には、正解率(Accuracy) 、Precision(適合率) 、Recall(再現率) 、F1-score 、そして 混同行列(Confusion Matrix) で確認します。
コードは以下の通りです。
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report
# 正解率
accuracy = accuracy_score(y_test, y_pred)
print(f"正解率(Accuracy): {accuracy:.2f}")
# Precision, Recall, F1-score の計算
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print(f"適合率(Precision): {precision:.2f}")
print(f"再現率(Recall): {recall:.2f}")
print(f"F1-score: {f1:.2f}")
# 混同行列の表示
conf_matrix = confusion_matrix(y_test, y_pred)
print("混同行列(Confusion Matrix):")
print(conf_matrix)
# 詳細な分類レポート
print("分類レポート:")
print(classification_report(y_test, y_pred))
コード解説
accuracy_score(y_test, y_pred)- 正解率(Accuracy) を計算する。これは「全体のデータのうち、何%を正しく分類できたか」を示す指標。
precision_score(y_test, y_pred)- 適合率(Precision) を計算する。これは「不良品(または悪性)と判定されたもののうち、実際に不良品(悪性)である割合」を示す。
recall_score(y_test, y_pred)- 再現率(Recall) を計算する。これは「実際に不良品(または悪性)のデータのうち、正しく検出できた割合」を示す。
- 医療分野では、悪性を見逃さないことが重要 なので、再現率を重視することが多い。
f1_score(y_test, y_pred)- F1スコア を計算する。これは Precision と Recall のバランスを取るための指標。
confusion_matrix(y_test, y_pred)- 混同行列 を出力する。分類モデルがどのクラスを誤分類しやすいのかを視覚的に確認できる。
classification_report(y_test, y_pred)- 分類レポート を出力する。各クラスごとの Precision・Recall・F1-score をまとめて表示してくれる。
では、これら指標について、ざっくりと解説してみましょう。僕自身は、分類問題では、まず正解率を確認するようにしています。ただし、データのバランスによってはモデルの性能を正しく評価できない場合があるので、その後に、適合率・再現率・F1スコアを確認し、モデルが「良性と悪性のどちらをうまく分類できているのか?」を確認するようにしています。特に、医療データでは 再現率(Recall)が重要 になることが多いです。僕みたいなおっさんは、年一回の健康診断の結果で「要注意」という診断が出ることがありますが、実際にその後、別の専門医に行ってみると、「何でもない」ということはよくあります。だからと言って、健康診断の結果が精度が悪いということではないんですね。医療場面では、健康な人を誤って「要注意」と誤診するリスクよりも、病気の人を誤って「問題なし」と誤診するリスクの方が高いため、こんな感じで、多めに「要注意」を出す傾向があります。
で、長くなりましたが、この考え方は、予測問題の分類モデルにも当てはまります。特に乳がん診断のようなケースでは、悪性腫瘍を見逃す(偽陰性)よりも、良性を誤って悪性と判定する(偽陽性)方がまだ安全です。なぜなら、後者の場合は追加の検査を行えば問題がないからです。一方、偽陰性の場合は病気を見逃してしまい、適切な治療が遅れるリスクがあります。そのため、機械学習モデルも 再現率(Recall)を高めることを優先する ように調整することが重要になります!
ということで、話を元に戻して、混同行列と正解率と再現率について見てみましょう。
混同行列は以下のように表されます。
| 実際のクラス ↓ / 予測のクラス → | 陽性 (Positive) | 陰性 (Negative) |
|---|---|---|
| 陽性 (Positive) | True Positive (TP) | False Negative (FN) |
| 陰性 (Negative) | False Positive (FP) | True Negative (TN) |
上の混同行列から、正解率と再現率は次のように計算します。
$$
正解率(Accuracy) = \frac{TP + TN}{TP + TN + FP + FN}
$$
$$
再現率(Recall) = \frac{TP}{TP + FN}
$$
正解率は、左上と右下の対角線上のデータ÷全データで計算され、再現率は、右上÷実際の陽性のデータで計算されます。特に再現率は陽性件数に占める陽性を当てた件数の割合であり、「陽性であることを予測できているか」に重きをおいた指標であるといえます。
準備が揃ったので、具体的な出力について確認していきましょう。
僕のPCでは次のように出力されました。
正解率(Accuracy): 0.95
適合率(Precision): 0.95
再現率(Recall): 0.97
F1-score: 0.96
混同行列(Confusion Matrix):
[[39 4]
[ 2 69]]
分類レポート:
precision recall f1-score support
0 0.95 0.91 0.93 43
1 0.95 0.97 0.96 71
accuracy 0.95 114
macro avg 0.95 0.94 0.94 114
weighted avg 0.95 0.95 0.95 114
混同行列(Confusion Matrix)について・・・
[[39 4]
[ 2 69]]混同行列は以下のように解釈できます。
| 実際のクラス ↓ / 予測のクラス → | 予測:0(良性) | 予測:1(悪性) |
|---|---|---|
| 実際:0(良性) | 39 (TN) | 4 (FP) |
| 実際:1(悪性) | 2 (FN) | 69 (TP) |
- TN(True Negative)= 39 → 実際に 良性 で、モデルも 良性 と予測した件数
- TP(True Positive)= 69 → 実際に 悪性 で、モデルも 悪性 と予測した件数
- FP(False Positive)= 4 → 実際は 良性 なのに、モデルが 悪性 と誤判定した件数(誤検出)
- FN(False Negative)= 2 → 実際は 悪性 なのに、モデルが 良性 と誤判定した件数(見逃し)
この結果から、モデルは 悪性(1)の検出が非常に良好 であり、良性(0)の誤検出が少しあることが分かります。
正解率(Accuracy)について・・・
全体の 114 件のデータのうち 95% を正しく分類 できたということです。かなり高い精度といえますね!
適合率(Precision)・・・
適合率(Precision)は、$ \frac{TP}{TP + FP} $で、「モデルが 悪性 と予測したうち、実際に悪性だった割合」です。つまり、悪性と判定した 73 件のうち、69 件が正解(悪性)だった ということです。これは、モデルが 不必要な悪性判定をあまりしていない(誤検出が少ない) ことを示しています。
再現率(Recall)・・・
解釈: 再現率(Recall)は、「実際に悪性のデータ のうち、どれだけ正しく悪性と分類できたか」の割合です。
つまり、71 件の実際の悪性腫瘍のうち、69 件を正しく検出 できました。再現率が 0.97(97%) と非常に高いため、モデルは 悪性の見逃し(偽陰性)がほとんどない ことを示しています!(実際、偽陰性は わずか 2 件 だけでした)
F1スコア(F1-score)・・・
F1スコアは$ \F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} $で Precision と Recall のバランスを取った指標 です。今回のモデルでは Precision(0.95)も Recall(0.97)も高いため、F1スコアも 0.96(96%) という良い値になっています。F1スコアが高いと、「誤検出(FP)も見逃し(FN)も少なく、バランスの良いモデル」と言えます。
クラスごとの分類レポート・・・
このレポートを詳しく見ると、以下のことが分かります。
precision recall f1-score support
0 0.95 0.91 0.93 43
1 0.95 0.97 0.96 71- 良性(クラス0)
- 適合率(Precision)= 0.95(良性と予測したデータの95%は実際に良性)
- 再現率(Recall)= 0.91(実際に良性のデータの91%を正しく良性と予測)
- F1スコア = 0.93(バランスの良い分類)
- 悪性(クラス1)
- 適合率(Precision)= 0.95(悪性と予測したデータの95%は実際に悪性)
- 再現率(Recall)= 0.97(実際に悪性のデータの97%を正しく悪性と予測)
- F1スコア = 0.96(Precision・Recall のバランスが良い)
良性(クラス0)の方が、やや見逃し(FN)が多くなっている ことが分かりますが、大きな問題ではなさそうです。
結論・・・
このモデルは 非常に高い精度(Accuracy = 95%)を持ち、悪性の見逃し(FN)もほとんどない ため、診断ツールとしては優秀な分類器と言えます。特に Recall(97%)が高い のは医療分野において重要なポイントで、悪性の患者を見逃しにくいというメリットがあります。とはいえ、誤検出(FP)が 4 件 あるため、良性の患者を誤って「悪性」と判定してしまうケースがあることも考慮する必要があります。この場合、追加の検査で誤判定を修正できるため、実際の医療現場でもある程度許容される範囲と言えるでしょう。
今回のモデルの結果から、もし「さらに悪性の見逃し(FN)を減らしたい!」という要件があれば、再現率(Recall)をさらに向上させるように、閾値を調整することも検討できます。一方で、誤検出(FP)が増えると不必要な精密検査が増えるため、そのバランスも重要になります。
ツリー図を出してみよう
では、決定木分析のメインイベント、ツリー図を出してみましょう。コードは以下の通りです。
from sklearn.tree import plot_tree
class_names = data.target_names
feature_names = data.feature_names
# 決定木の可視化
plt.figure(figsize=(30, 15))
plot_tree(clf, feature_names=feature_names, class_names=class_names, filled=True)
plt.show()
コード解説
class_names = data.target_names: クラス分類用のラベル名をセット。feature_names = data.feature_names: 決定木が使う特徴量の名前をセットplot_tree(clf, feature_names=feature_names, class_names=class_names, filled=True)- 決定木を可視化 する関数です。特徴量やクラス名を表示し、色付きでツリーを描画します。
結果は以下の通りです。
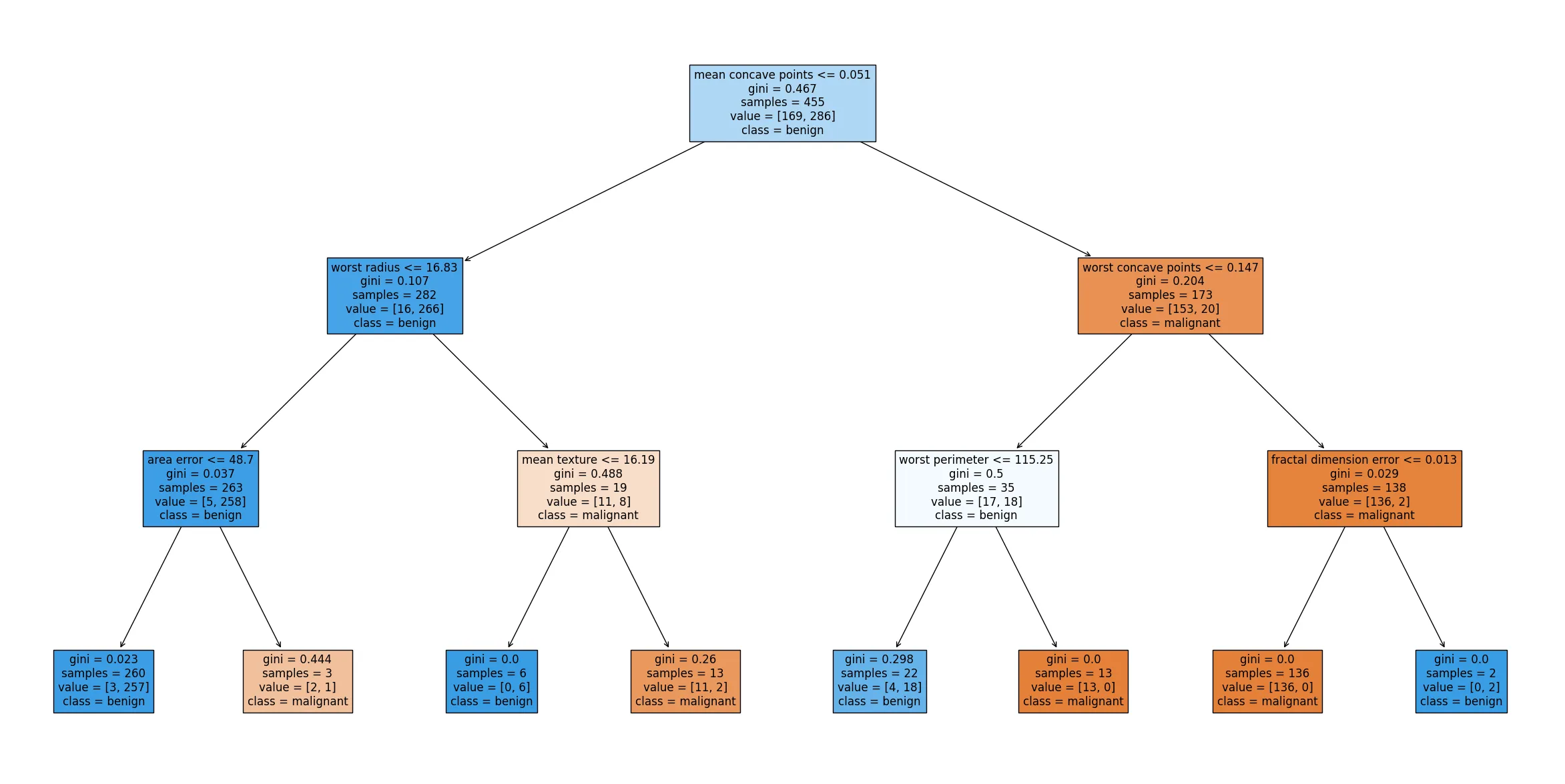
文字が細かいですが、結果を要約するとこうでした。
- 最初の分岐(ルートノード)
mean concave points(平均の凹みの数)が 0.05以下 かどうかで最初の分岐が行われる。- 0.05以下なら「左側」に進み、それより大きければ「右側」に進む。
- 左側(mean concave points ≤ 0.05 のケース)
worst radius(最大半径)≤ 16.83 の場合、さらにarea error(面積誤差)を確認する。- 面積誤差 ≤ 48.70 の場合 → class: 1(悪性)
- 面積誤差 > 48.70 の場合 → class: 0(良性)
worst radius > 16.83の場合、mean texture(平均テクスチャ)で分岐する。- 平均テクスチャ ≤ 16.19 の場合 → class: 1(悪性)
- 平均テクスチャ > 16.19 の場合 → class: 0(良性)
- 右側(mean concave points > 0.05 のケース)
worst concave points(最大の凹みの数)≤ 0.15 の場合、さらにworst perimeter(最大周囲長)で分岐する。- 最大周囲長 ≤ 115.25 の場合 → class: 1(悪性)
- 最大周囲長 > 115.25 の場合 → class: 0(良性)
worst concave points > 0.15の場合、fractal dimension error(フラクタル次元誤差)で分岐する。- フラクタル次元誤差 ≤ 0.01 の場合 → class: 0(良性)
- フラクタル次元誤差 > 0.01 の場合 → class: 1(悪性)
以上から、乳がんの診断には、mean concave points(平均の凹みの数) が最も重要な特徴になっており、続いて、worst radius(最大半径)や worst concave points(最大の凹みの数)も重要な指標であることがわかります。
まとめ
今回は、決定木を使った乳がん診断モデルの構築と評価を行いました。決定木は、データを分岐させながら分類するシンプルで直感的な機械学習アルゴリズムで、僕も現場ではめちゃめちゃ使っているモデルです。特にツリー図はでーた分析コンサル場面で重宝しています。
ぜひ、皆さんも本記事から、決定木を活用してもらえたら幸いです!