こんにちは、デジタルボーイです。今回はk-近傍法(k-Nearest Neighbor)をPythonとscikit-learnを使って構築したいと思います!

デジタルボーイです。
データサイエンス歴20年以上のおっさんです。中小企業診断士として、データサイエンス、WEBマーケティング、SEOに関するデータ分析、コンサルティングの仕事をしています。自己紹介の詳細はコチラ
Nearest Neighborsとは?
Nearest Neighbors(最近傍法)は、「あるデータが与えられたときに、その周囲にあるデータを探して、それらの情報をもとに予測を行う」というシンプルなアルゴリズムです。直感的には、「近いものは似ている」という考え方に基づいています。
この手法の代表的なものに k-Nearest Neighbors(k-NN) があります。これは、対象のデータに最も近い k個のデータ を見つけ、それらの特徴から分類や回帰を行う方法です。
例えば、下のようなグラフを考えてみてください。1
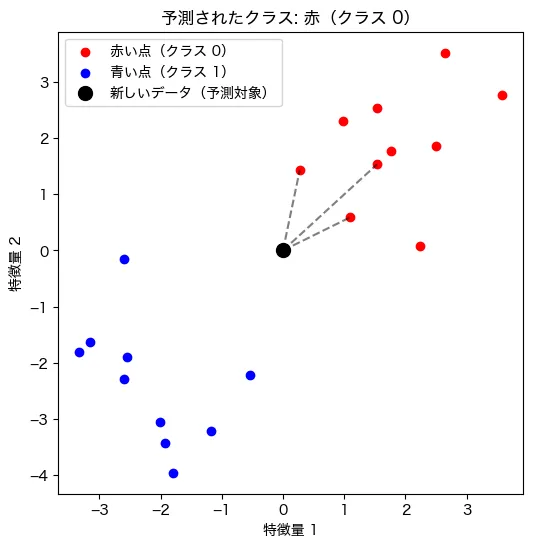
- 赤い点と青い点がデータとして存在
- 新しいデータ(黒い点)が登場
- この黒い点が どちらのグループに属するのか? を予測
k-NN では、黒い点の 近くにある点 を調べ、赤と青のどちらが多いかを確認することで分類します。
回帰モデルと比較したモデルの特徴
回帰分析とk-Nearest Neighbors(k最近傍法)の違いを直感的に説明すると、「数学の公式を作るか、それとも実際のデータを辞書のように記憶して調べるか」の違いと言えるでしょう。
例えば、僕がレストランのレビューを見て、「このお店の料理の味はどうだろう?」と考えたとします。回帰分析を使う場合は、過去のレビューや評価データを分析して、「価格 × 0.5 + 店の雰囲気 × 0.3 + シェフの経験年数 × 0.2 = 味のスコア」といった 計算式(回帰係数つきのモデル) を作り、新しいお店の味を予測します(実際にはこんなことしませんが。。。)。これは、データをもとに、数値的な関係を学習して一般化するイメージです。
一方、Nearest Neighborsは、「このお店の味を知りたかったら、過去に似たお店のレビューを直接見て判断しよう!」という考え方になります。数学の公式を作るのではなく、「この新しいお店は、以前行ったA店とB店に似ているから、その平均を取って予測しよう」と、データそのものを記憶し、近いデータを探す ことで答えを出します。
つまり、回帰分析ではデータから「味の良さを予測するための計算式(回帰係数つき)」を作るのに対し、Nearest Neighborsは「似たものを探して、それに基づいて答えを出す」だけなので、回帰係数のようなパラメータを学習する必要ないんですね!
k-Nearest Neighborsの応用場面
Nearest Neighborsはシンプルな仕組みですが、意外と幅広い分野で使われています。
1. 画像認識
例えば、手書きの数字を認識する場合、過去に学習した数字画像と 最も近いもの を見つけて判別することができます。手書き文字の分類や画像の類似検索に活用されます。
2. 推薦システム
ECサイトや動画サービスで、「あなたへのおすすめ」を表示する仕組みでも使われます。ユーザーの行動履歴と 似たユーザー を見つけ、その人が好んでいる商品や動画を推薦することができます!
3. 医療診断
患者の検査データをもとに、過去の 似た症例 を参照して病気の診断や治療方針を決めるといった用途にも使われます。特に、がんの診断などで活用されることがあります。
4. 異常検知
製造業やセキュリティの分野では、通常とは 異なるデータ を見つけるために活用されます。たとえば、クレジットカードの不正利用を検出する場合、普段の利用履歴と比べて 不自然な取引 を見つけることで、異常な行動を発見できます。
必要なライブラリのインポート
k近傍法を使うには、scikit-learnライブラリを利用します。まだインストールしていない場合は、以下のコマンドでインストールしてください
pip install scikit-learn numpy matplotlibpipを使ったインストール方法がわからない場合はこちらをご覧ください。



では、必要なライブラリをインポートしましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
これで準備完了です!次に、実際にk近傍法を使ったモデルの実装を行いましょう。
データの項目の確認、概要の確認
今回使用するデータは scikit-learn のワインデータセット とします。このデータセットは、異なる種類のワインを化学的な特徴量をもとに分類するためのものです。ワインの成分や特性が数値データとして記録されており、機械学習モデルを使ってワインの種類を分類することができます。
まず、データセットを読み込み、どのような項目があるのかを確認してみましょう!
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.datasets import load_wine
import pandas as pd
# データの読み込み
wine = load_wine()
# データをPandasのデータフレームに変換
df = pd.DataFrame(wine.data, columns=wine.feature_names)
# 最初の5行を表示
df.head()
コードの解説
load_wine()を使ってワインデータセットを読み込む。pd.DataFrame(wine.data, columns=wine.feature_names)で、scikit-learn のデータを pandas のデータフレームに変換。df.head()でデータの最初の5行を表示し、どのような値が含まれているのか確認。
データの上位5件の結果はこうでした。
| alcohol | malic_ acid | ash | alcalinity_ of_ash | magnesium | total_ phenols |
|---|---|---|---|---|---|
| 14.23 | 1.71 | 2.43 | 15.6 | 127 | 2.8 |
| 13.2 | 1.78 | 2.14 | 11.2 | 100 | 2.65 |
| 13.16 | 2.36 | 2.67 | 18.6 | 101 | 2.8 |
| 14.37 | 1.95 | 2.5 | 16.8 | 113 | 3.85 |
| 13.24 | 2.59 | 2.87 | 21 | 118 | 2.8 |
| flavanoids | nonflavanoid_ phenols | proanthocyanins | color_intensity | hue | od280/od315 of_diluted_wines | proline |
|---|---|---|---|---|---|---|
| 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065 |
| 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.4 | 1050 |
| 3.24 | 0.3 | 2.81 | 5.68 | 1.03 | 3.17 | 1185 |
| 3.49 | 0.24 | 2.18 | 7.8 | 0.86 | 3.45 | 1480 |
| 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735 |
このワインデータセットには 13個の特徴量 があります。それぞれ、ワインの化学的な成分や特性を示しており、具体的には アルコール含有量、リンゴ酸、マグネシウム含有量、フラボノイドなど が含まれています。ワインの種類は 3種類(class_0, class_1, class_2) に分類されており、これらを特徴量をもとに分類するのが今回の目的です。
分析の目的、ゴールを設定
今回の目的は、ワインの成分データをもとに、そのワインが どの種類に分類されるか を予測することとします。ワインは 3 つのクラス(class_0, class_1, class_2)に分類されており、それぞれ異なる特性を持っています。分類モデルとして k-Nearest Neighbors(k-NN) を使用し、新しいワインのデータが与えられたときに、どのクラスに属するかを推定するのがゴールとします!
k-NN は、未知のデータに対して「最も近い k 個のデータ」を調べ、周囲のデータが多いクラスに分類するというシンプルなアルゴリズムです。モデルの学習という概念はなく、データを保持しておき、予測時に計算を行う点が特徴です。今回は、この k-NN を使って ワインの種類を正しく予測できるか を検証しましょう!
モデルの実装
データを適切に分割し、k-NN を用いてワインの分類モデルを作成します。
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# データの準備
X = wine.data
y = wine.target
# 訓練データとテストデータに分割(8:2)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# k-NN モデルの作成(k=3)
knn = KNeighborsClassifier(n_neighbors=3)
# モデルの学習
knn.fit(X_train, y_train)
# 予測(テストデータに対して)
y_pred = knn.predict(X_test)
# 予測結果の出力(最初の10件)
print("予測ラベル:", y_pred[:10])
print("実際のラベル:", y_test[:10])
コードの解説
X = wine.data, y = wine.targetで、ワインデータの特徴量(成分情報)とターゲットラベルを取得。train_test_split(X, y, test_size=0.2, random_state=42)で、データを 訓練用(80%)とテスト用(20%)に分割。KNeighborsClassifier(n_neighbors=3)で k-NN モデルを作成(k=3)。knn.fit(X_train, y_train)で モデルを学習(この段階ではデータを保存しているだけ)。knn.predict(X_test)で テストデータに対して予測 を実施。print()で最初の10件の 予測結果と実際のラベルを出力 し、予測の傾向を確認。
僕の実行環境での結果はこうでした。
予測ラベル: [2 0 2 0 1 0 1 2 0 0]
実際のラベル: [0 0 2 0 1 0 1 2 1 2]ここまでで、モデルの学習と予測の流れが完成しました。あとは、このモデルがどのくらいの精度でワインを分類できるのかを、次のステップで評価していきます。果たして、うまく分類できるのか…楽しみですね!
モデルの評価
作成した k-NN モデルがどの程度正しくワインの種類を分類できるかを評価します。回帰モデルでは MSE(平均二乗誤差)、RMSE(平方根平均二乗誤差)、R²(決定係数)を用いるのが一般的ですが、今回は 分類問題 なので、適切な評価指標として 正解率(Accuracy) を使用します。また、より詳しくモデルの性能を知るために、混同行列(Confusion Matrix) や 分類レポート(Precision, Recall, F1-score) も確認します。
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 正解率(Accuracy)
accuracy = accuracy_score(y_test, y_pred)
# 混同行列(Confusion Matrix)
conf_matrix = confusion_matrix(y_test, y_pred)
# 分類レポート(Precision, Recall, F1-score)
class_report = classification_report(y_test, y_pred, target_names=wine.target_names)
# 結果の表示
print(f"正解率(Accuracy): {accuracy:.2f}")
print("\n混同行列(Confusion Matrix):\n", conf_matrix)
print("\n分類レポート(Classification Report):\n", class_report)
コードの解説
accuracy_score(y_test, y_pred)で モデルの正解率 を算出。正解率は「正しく分類できた割合」を示し、シンプルな評価基準 となる。confusion_matrix(y_test, y_pred)で 混同行列 を計算。これは どのクラスがどのクラスと間違えられたか を可視化できる。classification_report(y_test, y_pred, target_names=wine.target_names)で Precision(適合率), Recall(再現率), F1-score(バランス指標) を計算。精度の詳細を確認するのに役立つ。print(f"正解率(Accuracy): {accuracy:.2f}")で 小数第2位までの正解率 を表示。print(conf_matrix)で 混同行列を表示 し、どのクラスが誤分類されたかを確認。print(class_report)で クラスごとの詳細な評価結果 を出力。
僕の実行環境の結果はこうでした。
正解率(Accuracy): 0.81
混同行列(Confusion Matrix):
[[12 0 2]
[ 1 11 2]
[ 1 1 6]]
分類レポート(Classification Report):
precision recall f1-score support
class_0 0.86 0.86 0.86 14
class_1 0.92 0.79 0.85 14
class_2 0.60 0.75 0.67 8
accuracy 0.81 36
macro avg 0.79 0.80 0.79 36
weighted avg 0.82 0.81 0.81 36
モデルの評価結果の解釈
正解率(Accuracy)
正解率は 81% であり、全体として まずまずの精度 です。ワインの分類問題としては悪くはありませんが、100% ではないため、誤分類も一定数発生していることが分かります。特に、クラスごとの詳細を確認することで、どの部分で誤分類が発生しやすいかを分析できます。
混同行列(Confusion Matrix)
混同行列を詳しく見てみましょう。
混同行列(Confusion Matrix):
[[12 0 2]
[ 1 11 2]
[ 1 1 6]]各行は「実際のクラス」、各列は「予測されたクラス」を表します。例えば、class_0 の場合、12個は正しく class_0 に分類されたものの、2個が class_2 に誤分類 されています。同様に、class_1 では 11 個が正しく分類されたものの、1 個が class_0 に、2 個が class_2 に誤分類されています。class_2 に関しては 6個が正しく分類 されたものの、1個が class_0 に、1個が class_1 に誤分類されています。
つまり、特に class_2 の分類が難しい ことが分かります。class_0 や class_1 は比較的良好な分類精度ですが、class_2 については誤分類率が高めであり、モデルの改善が必要かもしれません。
3. Precision(適合率)、Recall(再現率)、F1-score
| クラス | Precision (適合率) | Recall (再現率) | F1-score | サポート数 |
|---|---|---|---|---|
class_0 | 0.86 | 0.86 | 0.86 | 14 |
class_1 | 0.92 | 0.79 | 0.85 | 14 |
class_2 | 0.60 | 0.75 | 0.67 | 8 |
- Precision(適合率) は、予測したクラスがどれだけ正しく分類されているかを示します。
class_1が 0.92 と高く、最も精度が良いことが分かります。class_2の適合率は 0.60 と低く、他のクラスと誤分類されやすい傾向にあります。 - Recall(再現率) は、本来そのクラスであるデータをどれだけ正しく分類できたかを示します。
class_2は 0.75 なので、class_1の 0.79 と比べると多少良いですが、完璧ではありません。 - F1-score(バランス指標) は Precision と Recall のバランスを取った値です。
class_0とclass_1は 0.85~0.86 と良好ですが、class_2は 0.67 と低めです。
特徴量の重要度
k-NN は「近いデータほど似ている」というシンプルなアルゴリズムなので、どの特徴量が分類に強く影響を与えているのかを直接知るのは難しいです。しかし、特徴量の寄与度を調べる方法はいくつかあります。例えば、sklearnの permutation_importanceというものを使うことで、特徴量をsklearnが適当に抜き差ししながら、予測精度への重要度を出力してくれる機能があります。
from sklearn.inspection import permutation_importance
feature_names = wine.feature_names
# 特徴量の重要度を計算(Permutation Importance)
perm_importance = permutation_importance(knn, X_test, y_test, n_repeats=10, random_state=42)
importance_df = pd.DataFrame({'特徴量': feature_names, '重要度': perm_importance.importances_mean})
importance_df = importance_df.sort_values(by='重要度', ascending=False)
# 結果の可視化
plt.figure(figsize=(10, 5))
plt.barh(importance_df['特徴量'], importance_df['重要度'], color='steelblue')
plt.xlabel("特徴量の重要度")
plt.ylabel("特徴量")
plt.title("k-NN における特徴量の重要度")
plt.gca().invert_yaxis() # 重要度の高いものを上に
plt.show()結果はこんな感じです。
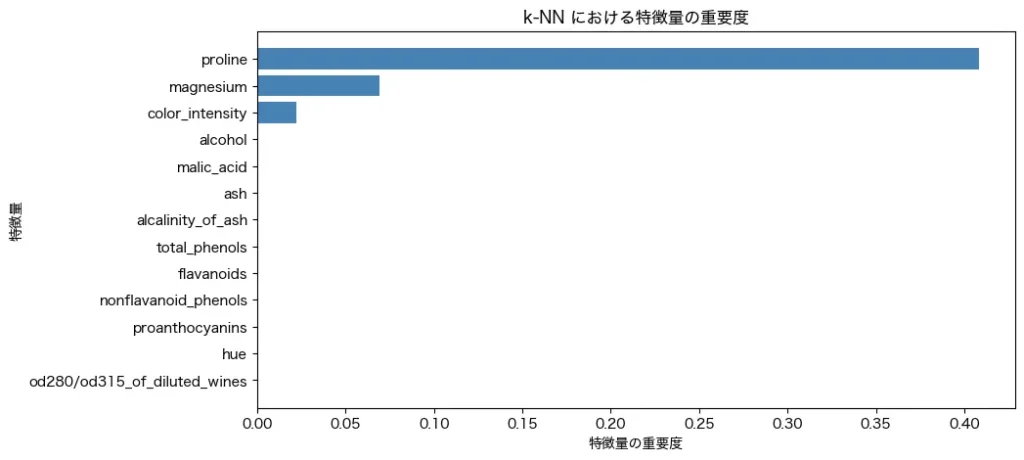
prolineとmagnesiumの値が、予測に影響をしていることがわかりますね!
プロリン(Proline)はワインに含まれる アミノ酸の一種 で、ワインの香りや風味に影響を与える成分らしいです。一般的に、ワインの熟成度や品種の違いによってプロリンの含有量が変わるため、ワインの種類を分類する際に重要な指標となるとのこと。 また、マグネシウム(Magnesium)はワインに含まれる ミネラル成分 のひとつで、酵母の発酵を助けたり、ワインの味わいに影響を与える要素らしいです。
結果のプロット
上述のようにプロリンとマグネシウムが分類に役立っているということなので、この2つのデータを用いて、各クラスの散布図を描いてみましょう。
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.preprocessing import StandardScaler
# プロリンとマグネシウムの特徴量を抽出
X_proline = wine.data[:, wine.feature_names.index('proline')]
X_magnesium = wine.data[:, wine.feature_names.index('magnesium')]
# データを標準化(スケールの影響を抑えるため)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(np.column_stack((X_proline, X_magnesium)))
# クラスごとの色を設定
class_labels = wine.target
colors = ['red', 'blue', 'green']
class_names = wine.target_names
# 散布図をプロット
plt.figure(figsize=(8, 6))
for i, class_name in enumerate(class_names):
plt.scatter(
X_scaled[class_labels == i, 0],
X_scaled[class_labels == i, 1],
color=colors[i],
label=class_name,
alpha=0.7
)
# 軸ラベルとタイトル
plt.xlabel("プロリン(Proline, 標準化)")
plt.ylabel("マグネシウム(Magnesium, 標準化)")
plt.title("プロリンとマグネシウムを軸にしたワイン分類の散布図")
plt.legend()
plt.grid(True)
plt.show()
コードの解説
wine.data[:, wine.feature_names.index('proline')]で プロリンのデータ を取得。wine.data[:, wine.feature_names.index('magnesium')]で マグネシウムのデータ を取得。StandardScaler()で 標準化 し、スケールの違いによる影響を抑える。for i, class_name in enumerate(class_names)で クラスごとに色分けして散布図を作成。plt.scatter(..., color=colors[i], label=class_name, alpha=0.7)で クラスごとに色を変えたプロット を実施。plt.xlabel(),plt.ylabel()で 軸ラベルを日本語で表示。plt.legend()で ワインの種類を凡例として表示。
結果はこうでした。
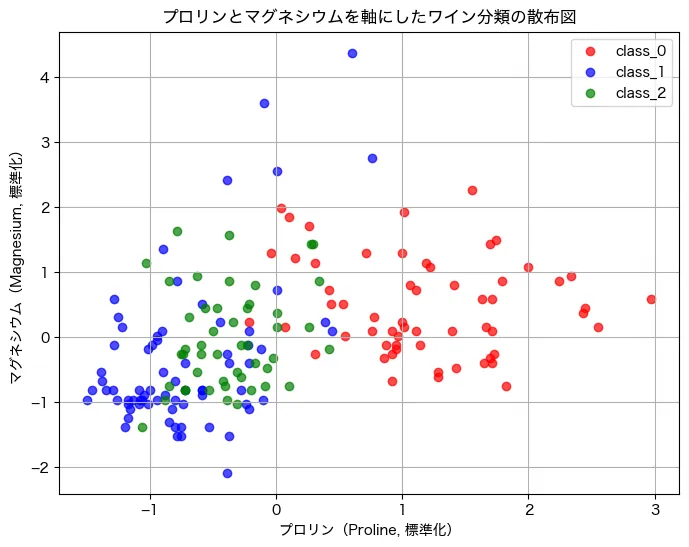
2軸ですが、うまく、クラスごとに固まっているのがみて取れますね!左下にclass1(青)、中央にclass2(緑)、右端にclass0(赤)でした。
まとめ
以上、k-NN(k-Nearest Neighbors)の解説でした!このモデルは「近くのデータほど似ている」という考え方に基づくシンプルな分類アルゴリズムです。ワインデータを使い、分類モデルを構築・評価しました。結果、プロリンとマグネシウムが分類に大きく寄与していることが判明しましたね。一般的には、他のモデルに比べてめちゃめちゃ精度の高いモデルというわけではないですが、安定してそこそこの精度はモデルで、かつ、個人的には外れ値にも強いように感じています。
予測モデルを構築しなければならないケースでは、いろんなモデルを試す中で、このモデルも作ってみるということはよくあります。ぜひ、実際にチャレンジしてみてください!