こんにちは、デジタルボーイです。今回は回帰モデルの中の1モデル、ロジスティック回帰モデルについて、Pythonとscikit-learnを使い、解説したいと思います!
ちなみにこれまで、単回帰分析、重回帰分析についても解説しています。ロジスティック回帰モデルはこれらのモデルの応用モデルと言えるので、必要があれば以下の解説を先におさらいしてみてください。


デジタルボーイです。
データサイエンス歴20年以上のおっさんです。中小企業診断士として、データサイエンス、WEBマーケティング、SEOに関するデータ分析、コンサルティングの仕事をしています。自己紹介の詳細はコチラ
ロジスティック回帰分析とは?
ロジスティック回帰(Logistic Regression)は、2値分類問題を解くための代表的な機械学習モデルです。このモデルは、入力データから0または1といった2つのクラスに分類するために使用されます。例えば、以下のような場面で利用されます。
- スパムメール分類(メールがスパムかどうか)
- 顧客の購買予測(特定の商品を購入するかどうか)
- 医療診断(患者が特定の病気にかかっているかどうか)
モデルの直感的な理解
ロジスティック回帰は、入力値 xxx に対して、確率 ppp を出力します。この確率が0.5以上なら「1」、それ未満なら「0」と分類します。数式では以下のように表されます。
$$
p = \frac{1}{1 + e^{-(w x + b)}}
$$
この式により、出力が0から1の間の確率として表現されるため、分類問題に適しています。
ロジスティック回帰の特徴を視覚的に理解するために、データと2値を決定する閾値を示すプロットを見てみましょう。
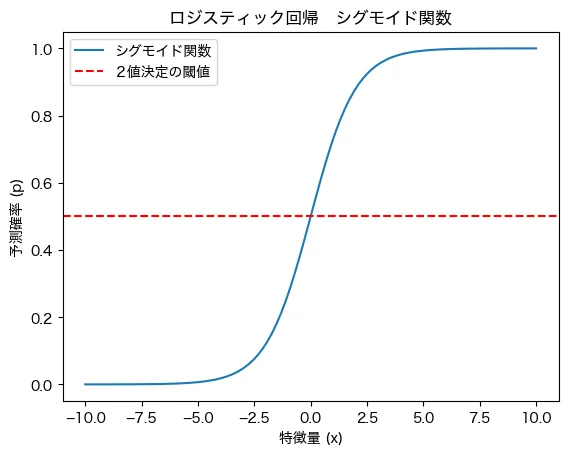
これは特徴量であるxが増加するにつれて、予測値が上がっており、その下限と上限は0〜1となっています。この曲線はロジスティック回帰分析が予測する予測値の曲線で、シグモイド関数と言われています。
また、予測値は連続的な値として算出されますが、そこから2値を割り振るための閾値が赤い点線になります。予測値がこれより上だったら1、そうでなければ0というように割り振る流れになります。
ロジスティック回帰の応用場面
ロジスティック回帰は、多くの実世界の問題で利用されています。例えばこんな感じです。
- マーケティング
- 顧客が広告をクリックするか(クリック率予測)
- ユーザーがサブスクリプションを解約するか(解約予測)
- 医療
- 患者が特定の病気を持っているか(診断補助)
- 手術成功率の予測
- 金融
- クレジットカードの不正利用検出
- ローンの返済遅延リスクの予測
- 製造業
- 製品が不良品かどうかの分類
- センサー情報から機械の異常を検知
必要なライブラリのインポート
ラッソ回帰を実装するためには、以下のライブラリが必要です。インストールしていない場合は、先に pip install しましょう。
pip install numpy pandas matplotlib scikit-learnpipを使ったインストール方法はこちらになります。



まずは、必要なライブラリをインポートしましょう。
インポートするライブラリは以下の通りです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
コードの解説
numpyとpandasはデータ処理のために使用matplotlib.pyplotは可視化に使用train_test_splitはデータを学習用とテスト用に分割StandardScalerは特徴量のスケーリングを行うLogisticRegressionはロジスティック回帰モデルaccuracy_scoreなどはモデル評価のために使用
データ概要の確認
今回は scikit-learn に含まれる 乳がん診断データセット(breast_cancer)を使用します。このデータセットは、腫瘍が良性(0)か悪性(1)かを分類するタスクに適しています。
まずはデータの概要を確認してみましょう。
from sklearn.datasets import load_breast_cancer
# データの読み込み
data = load_breast_cancer()
X = data.data
y = data.target
# データの概要を表示
print("特徴量の数:", X.shape[1])
print("データのサンプル数:", X.shape[0])
print("クラスの分布:", np.bincount(y))
print("特徴量の名前:", data.feature_names)
コードの解説
load_breast_cancer()で乳がんデータセットをロードX.shape[1]で特徴量の数を取得X.shape[0]でデータのサンプル数を取得np.bincount(y)でクラスごとのデータ数を確認data.feature_namesで特徴量の名前を確認
アウトプットはこんな感じです。
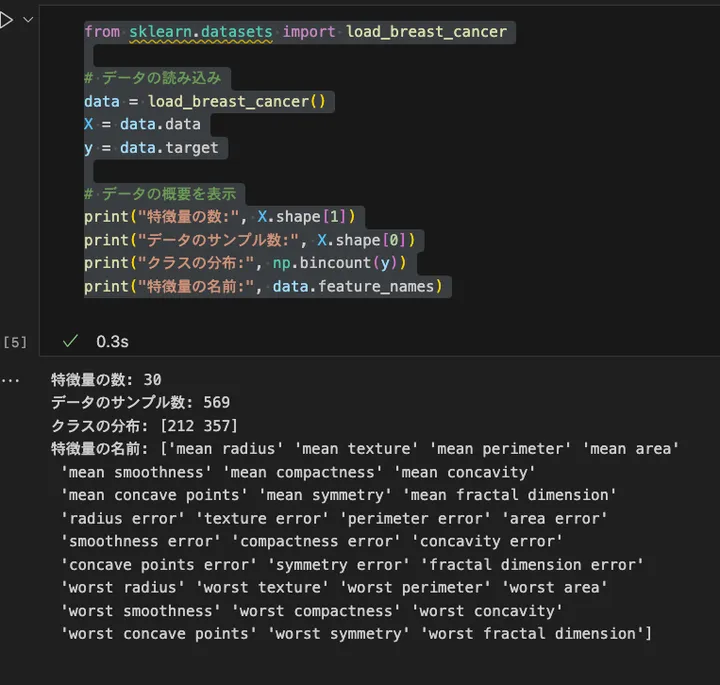
このデータセットには 30個の特徴量 があり、それぞれが乳がんの発症に関連しています。クラスの分布は、未発症が0(212件)、発症が1(357件)となっています。
分析の目的とゴール
今回の分析の目的は、乳がん診断データセットを用いて、腫瘍が良性か悪性かをロジスティック回帰モデルで分類することです。
このモデルを構築することで、以下のゴールを達成します。
ゴール
- 医療診断の支援
モデルが学習したデータをもとに、新しい患者のデータを分類し、良性または悪性の腫瘍を予測する - モデルの精度評価
予測結果を評価し、どの程度の正確さで分類できるかを確認する - 重要な特徴量の把握
どの特徴が分類に影響を与えているのかを確認し、解釈を試みる
モデルの実装
ロジスティック回帰モデルを構築し、乳がんデータセットを学習させます。
# データの準備
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# データの標準化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# モデルの学習
model = LogisticRegression()
model.fit(X_train_scaled, y_train)
# 予測
y_pred = model.predict(X_test_scaled)
コードの解説
train_test_split()を使い、データを80%を学習用、20%をテスト用に分割StandardScaler()で特徴量のスケーリングを行い、モデルの収束を助けるLogisticRegression()を用いてモデルを学習し、fit()を実行predict()を使い、テストデータに対して予測を行う
モデルの評価
ロジスティック回帰モデルの評価には、以下の指標を使用します。
- 正解率 (Accuracy):正しく分類された割合
- 混同行列 (Confusion Matrix):分類結果を詳細に確認
- 適合率, 再現率, F1スコア:より詳細な分類評価指標
また、回帰モデルとは異なり、MSE (平均二乗誤差), RMSE (平方根平均二乗誤差), R²乗 (決定係数) は使用しません。代わりに分類問題に適した評価指標を用います。
# モデル評価
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
# 結果の出力
print("正解率:", accuracy)
print("混同行列:\n", conf_matrix)
print("詳細レポート:\n", report)
コードの解説
accuracy_score(y_test, y_pred)で正解率を算出confusion_matrix(y_test, y_pred)で混同行列を出力classification_report(y_test, y_pred)で適合率、再現率、F1スコアをまとめたレポートを表示
結果はこうでした。
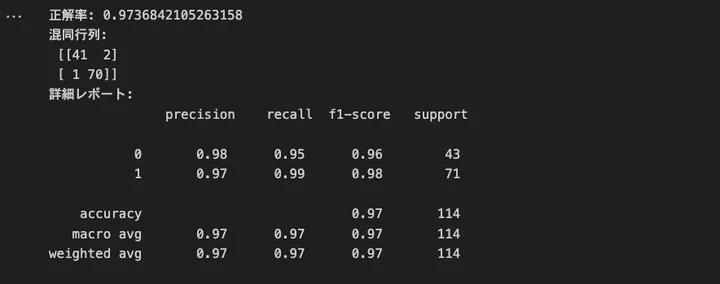
正解率が97.3%とかなりいい感じに予測できていることがわかります。また、 アウトプットにある「混同行列」は、モデルの分類結果を 「実際のクラス」と「予測クラス」 の対応で整理したものです。結果はこんな感じで見ることができます。
混同行列の見方:
---------------
[[TN FP]
[FN TP]]- TN (True Negative): 実際にネガティブ(クラス0)で、モデルもネガティブと予測した数
- FP (False Positive): 実際はネガティブ(クラス0)だが、モデルが誤ってポジティブと予測した数
- FN (False Negative): 実際はポジティブ(クラス1)だが、モデルが誤ってネガティブと予測した数
- TP (True Positive): 実際にポジティブ(クラス1)で、モデルもポジティブと予測した数
で、今回の混同行列は実際には以下の結果でした。
混同行列:
[[41 2]
[ 1 70]]各値は以下に対応します。
それぞれの値の意味
- 41 (TN) → 実際にネガティブで、正しくネガティブと予測されたデータ数
- 2 (FP) → 実際はネガティブなのに、誤ってポジティブと予測されたデータ数(偽陽性)
- 1 (FN) → 実際はポジティブなのに、誤ってネガティブと予測されたデータ数(偽陰性)
- 70 (TP) → 実際にポジティブで、正しくポジティブと予測されたデータ数
ここから、それぞれの評価指標も計算できます。
- 正解率 (Accuracy)
(TP + TN) / 全データ数 = (70 + 41) / (41 + 2 + 1 + 70) = 111 / 114 ≈ 97.37%
- 適合率 (Precision, 陽性的中率)
TP / (TP + FP) = 70 / (70 + 2) = 70 / 72 ≈ 97.22%
- 再現率 (Recall, 真陽性率)
TP / (TP + FN) = 70 / (70 + 1) = 70 / 71 ≈ 98.59%
- F1スコア (Precision と Recall のバランス指標)
2 * (Precision * Recall) / (Precision + Recall) ≈ 97.90%
つまり、正解率97.37%と高いが、2件の誤分類 (FP) がある。これは、実際にネガティブなのに誤ってポジティブと予測されるケースが発生(例: 「がんではないのにがんと診断」)。また、ポジティブクラスの予測精度が高いつまり、70件中1件しか間違えていない(FN = 1)ということが言えます。
結果をグラフで確認
では、実際の予測状況をグラフでも確認してみましょう。ちょっと長いですが、こんな感じです。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import confusion_matrix
# 日本語フォント設定(Mac用)
plt.rcParams["font.family"] = "Hiragino sans"
# 混同行列の取得
conf_matrix = confusion_matrix(y_test, y_pred)
# 混同行列の値
tn, fp, fn, tp = conf_matrix.ravel()
# 正解・不正解率の計算
total_pos = tp + fn # 実際のポジティブの総数
total_neg = tn + fp # 実際のネガティブの総数
pos_correct_rate = tp / total_pos if total_pos > 0 else 0 # ポジティブの正解率
pos_incorrect_rate = fn / total_pos if total_pos > 0 else 0 # ポジティブの不正解率
neg_correct_rate = tn / total_neg if total_neg > 0 else 0 # ネガティブの正解率
neg_incorrect_rate = fp / total_neg if total_neg > 0 else 0 # ネガティブの不正解率
# 構成比の積み上げグラフのデータ
rates = np.array([[pos_correct_rate, pos_incorrect_rate],
[neg_correct_rate, neg_incorrect_rate]])
# 実数の積み上げグラフのデータ
counts = np.array([[tp, fn],
[tn, fp]])
labels = ["ポジティブ", "ネガティブ"]
categories = ["正解", "不正解"]
colors = ["#1f77b4", "#ff7f0e"] # 正解(青)・不正解(オレンジ)
# サブプロットの作成
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# 構成比の積み上げグラフ
axes[0].bar(labels, rates[:, 0], label="正解", color=colors[0])
axes[0].bar(labels, rates[:, 1], bottom=rates[:, 0], label="不正解", color=colors[1])
axes[0].set_ylabel("構成比")
axes[0].set_title("ポジティブ・ネガティブの正解/不正解率(構成比)")
axes[0].legend()
# 実数の積み上げグラフ
axes[1].bar(labels, counts[:, 0], label="正解", color=colors[0])
axes[1].bar(labels, counts[:, 1], bottom=counts[:, 0], label="不正解", color=colors[1])
axes[1].set_ylabel("件数")
axes[1].set_title("ポジティブ・ネガティブの正解/不正解数(実数)")
axes[1].legend()
# グラフの表示
plt.tight_layout()
plt.show()
コードの解説
plt.rcParams["font.family"] = "Hiragino sans"- Mac用の日本語フォントを指定。Windowsの場合は、
plt.rcParams["font.family"] = "Meiryo"]などにする。
- Mac用の日本語フォントを指定。Windowsの場合は、
confusion_matrix(y_test, y_pred)- 実際のラベル (
y_test) と予測値 (y_pred) から混同行列を作成する。
- 実際のラベル (
tn, fp, fn, tp = conf_matrix.ravel()- 混同行列の各要素を取得する。
tn(True Negative):実際にネガティブで正しくネガティブと予測された数fp(False Positive):実際にはネガティブだがポジティブと誤予測された数fn(False Negative):実際にはポジティブだがネガティブと誤予測された数tp(True Positive):実際にポジティブで正しくポジティブと予測された数
total_pos = tp + fn- 実際にポジティブなデータの総数を計算する。
total_neg = tn + fp- 実際にネガティブなデータの総数を計算する。
pos_correct_rate = tp / total_pos if total_pos > 0 else 0- ポジティブデータに対する正解率(ポジティブを正しくポジティブと予測した割合)を計算する。
pos_incorrect_rate = fn / total_pos if total_pos > 0 else 0- ポジティブデータに対する不正解率(ポジティブをネガティブと誤予測した割合)を計算する。
neg_correct_rate = tn / total_neg if total_neg > 0 else 0- ネガティブデータに対する正解率(ネガティブを正しくネガティブと予測した割合)を計算する。
neg_incorrect_rate = fp / total_neg if total_neg > 0 else 0- ネガティブデータに対する不正解率(ネガティブをポジティブと誤予測した割合)を計算する。
rates = np.array([[pos_correct_rate, pos_incorrect_rate], [neg_correct_rate, neg_incorrect_rate]])- ポジティブとネガティブに対する正解率・不正解率を配列として格納する。
counts = np.array([[tp, fn], [tn, fp]])- ポジティブとネガティブに対する正解・不正解の実数を配列として格納する。
labels = ["ポジティブ", "ネガティブ"]- グラフのx軸ラベルを設定。
colors = ["#1f77b4", "#ff7f0e"]- グラフの色を設定。(青=正解、オレンジ=不正解)
グラフの描画部分
fig, axes = plt.subplots(1, 2, figsize=(12, 6))- 1行2列のサブプロットを作成し、グラフを並べる。
axes[0].bar(labels, rates[:, 0], label="正解", color=colors[0])- 左側のグラフで、正解率の積み上げ棒グラフを描画する。
axes[0].bar(labels, rates[:, 1], bottom=rates[:, 0], label="不正解", color=colors[1])- その上に不正解率の積み上げ棒グラフを描画する。
axes[0].set_ylabel("構成比")- y軸ラベルを「構成比」に設定。
axes[0].set_title("ポジティブ・ネガティブの正解/不正解率(構成比)")- グラフタイトルを設定。
axes[0].legend()- 凡例を表示。
axes[1].bar(labels, counts[:, 0], label="正解", color=colors[0])- 右側のグラフで、正解数の積み上げ棒グラフを描画する。
axes[1].bar(labels, counts[:, 1], bottom=counts[:, 0], label="不正解", color=colors[1])- その上に不正解数の積み上げ棒グラフを描画する。
axes[1].set_ylabel("件数")- y軸ラベルを「件数」に設定。
axes[1].set_title("ポジティブ・ネガティブの正解/不正解数(実数)")- グラフタイトルを設定。
axes[1].legend()- 凡例を表示。
plt.tight_layout()- レイアウトを調整し、グラフの間隔を適切に設定。
plt.show()- グラフを表示。
結果はこんな感じです。
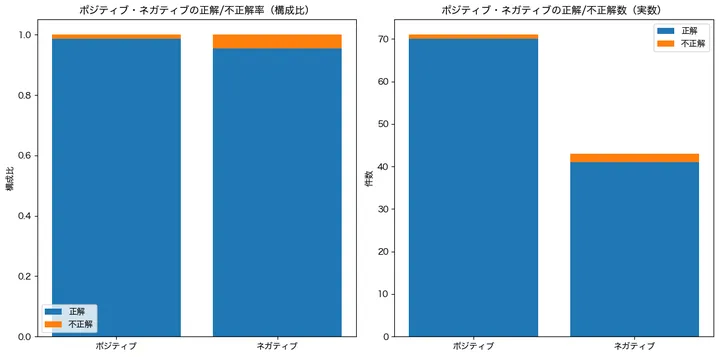
左側は正解と不正解の構成比をポジティブ(陽性)とネガティブ(陰性)ごとにプロットしています。ネガティブの方が不正解の率が高いことが見て取れます。また、右側は実数をプロットしています。実数で見ても、ネガティブ(陰性)の方が不正解のボリュームは多いことが見えますね!
変数の重要度
最後に、ロジスティック回帰の予測にどの特徴量(変数)が効いているのかを見てみましょう。
import matplotlib.pyplot as plt
import numpy as np
# 日本語フォント設定(Mac用)
plt.rcParams["font.family"] = "Hiragino sans"
# モデルの係数取得
coefficients = model.coef_[0] # ロジスティック回帰の各特徴量の重み
feature_names = data.feature_names # 特徴量の名前
# 係数の絶対値の大きい順にソート
sorted_indices = np.argsort(np.abs(coefficients))[::-1]
sorted_features = np.array(feature_names)[sorted_indices]
sorted_coefficients = coefficients[sorted_indices]
# プロット
plt.figure(figsize=(10, 6))
plt.barh(sorted_features[:10], sorted_coefficients[:10], color="steelblue") # 上位10特徴量のみ表示
plt.xlabel("回帰係数の値")
plt.ylabel("特徴量")
plt.title("ロジスティック回帰の説明変数の重要度")
plt.gca().invert_yaxis() # 上位の特徴量を上にする
# グラフの表示
plt.show()
コードの解説
plt.rcParams["font.family"] = "Hiragino sans"- Mac用の日本語フォントを指定。Windowsの場合は、
plt.rcParams["font.family"] = "Meiryo"]などにする。
- Mac用の日本語フォントを指定。Windowsの場合は、
coefficients = model.coef_[0]- ロジスティック回帰の学習済みモデル
modelから各特徴量の重み(回帰係数)を取得する。
- ロジスティック回帰の学習済みモデル
feature_names = data.feature_names- データセットに含まれる特徴量の名前を取得する。
sorted_indices = np.argsort(np.abs(coefficients))[::-1]- 係数の絶対値を降順(影響が大きい順)に並べる。
sorted_features = np.array(feature_names)[sorted_indices]- ソートした順番に特徴量の名前を並べる。
sorted_coefficients = coefficients[sorted_indices]- ソートした順番に係数の値を並べる。
plt.figure(figsize=(10, 6))- プロットのサイズを指定する。
plt.barh(sorted_features[:10], sorted_coefficients[:10], color="steelblue")- 上位10個の特徴量を棒グラフで描画する。
plt.xlabel("回帰係数の値")- x軸ラベルを設定する。
plt.ylabel("特徴量")- y軸ラベルを設定する。
plt.title("ロジスティック回帰の説明変数の重要度")- グラフのタイトルを設定する。
plt.gca().invert_yaxis()- グラフの並びを逆にし、影響が大きい特徴量を上に表示する。
plt.show()- グラフを表示する。
結果はこうでした。
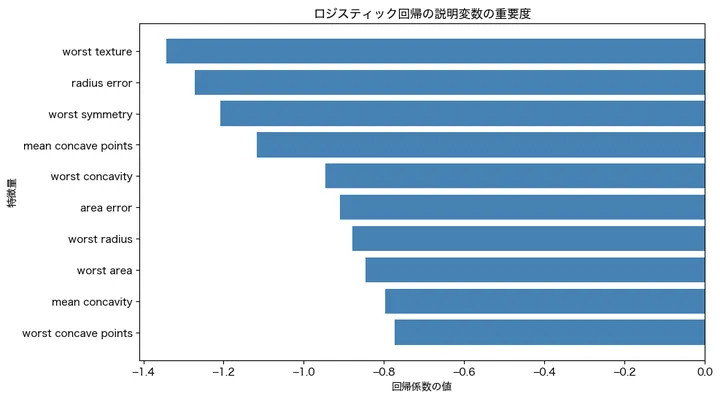
ロジスティック回帰モデルの予測において、worst texture(最も悪いテクスチャ)、radius error(半径の誤差)、worst symmetry(最も悪い対称性)、mean concave points(凹点の平均数)の4つの変数が特に重要でした。
worst textureは、腫瘍の組織の模様の粗さを表し、悪性腫瘍は異常増殖により組織の密度や形状が不均一になりやすいため、この値が高いほど悪性の可能性が高まります。
radius errorは、腫瘍の半径のばらつきを示し、良性の腫瘍が比較的均一な円形であるのに対し、悪性の腫瘍は不規則な形を持つことが多く、半径のばらつきが大きくなるため、この値が大きいほど悪性である可能性が高いと考えられます。
worst symmetryは、腫瘍の対称性の崩れ具合を示し、良性の腫瘍は比較的円形で対称性が高いのに対し、悪性の腫瘍は異常増殖により形が不規則になり左右対称性が失われるため、この値が大きいほど悪性の可能性が高まります。
mean concave pointsは、腫瘍の境界線における「へこみ」の数の平均値を示し、良性の腫瘍は滑らかな境界線を持つのに対し、悪性の腫瘍は不規則な増殖によって境界がギザギザになり、凹点の数が増えるため、この値が大きいほど悪性である可能性が高くなります。
これらの変数はすべて腫瘍の形状や境界の不規則性に関係しており、特に「半径の誤差」「凹点の平均数」「対称性の悪さ」は悪性腫瘍に特徴的なパターンを捉えているため、診断の精度向上に貢献している可能性があります。
まとめ
この分析では、ロジスティック回帰モデルを用いて、乳がんデータセットの腫瘍が良性か悪性かを分類しました。モデルの性能評価には、混同行列を使用し、ポジティブ(悪性)・ネガティブ(良性)それぞれに対する正解率と不正解率を計算しました。可視化として、正解・不正解の構成比を積み上げグラフで示し、分類のバランスを確認しました。また、実際の正解数・不正解数の積み上げグラフを描画し、誤分類の傾向を明確にしました。これにより、モデルがどの程度信頼できるかや、誤分類の影響を直感的に理解できます。結果を活用することで、医療診断の補助や分類モデルの改善に役立てることができます。