こんにちは、デジタルボーイです。今回は機械学習における予測モデルについて、さまざまな手法や前処理、モデル選定方法までを含めてざっくりと解説します。データサイエンスに関心のある方や、これからモデル構築に挑戦しようとしている方に向けた内容です。

デジタルボーイです。
データサイエンス歴20年以上のおっさんです。中小企業診断士として、データサイエンス、WEBマーケティング、SEOに関するデータ分析、コンサルティングの仕事をしています。自己紹介の詳細はコチラ
予測モデルとは
予測モデルはその名の通り「予測」をするための「モデル」です。
ここで予測というのは、「未知のデータを特定の根拠を持って、予め(あらかじめ)推し測る(推し測る)こと」をいいます。典型的な例で言うと、次のように過去のデータを根拠に将来の値を予想することになります。
次にモデルというのは統計やデータサイエンスの場面で言うと、「データの背後にある法則性やパターンを数式やアルゴリズムで表現した数理的手法」に当たります。
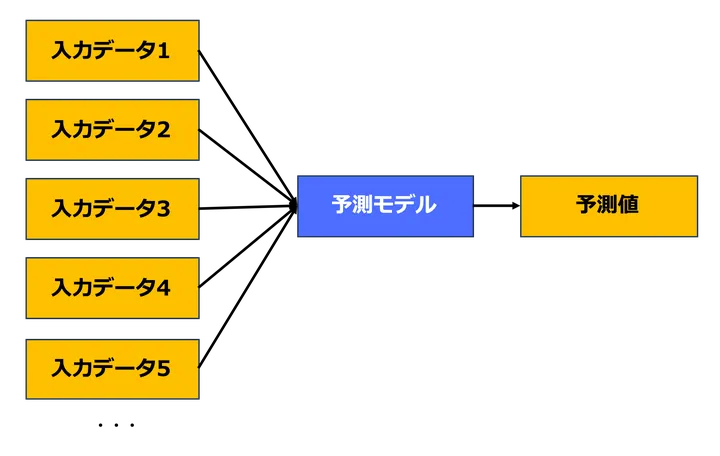
つまり、予測モデルというのは既知のデータを用いて、「未来の値」や「未知の値」を予測するために作られた数理的手法のことになります。次のような図をイメージするとわかりやすいと思います。図の入力データが「既知のデータ」、真ん中の青いものが「予測モデル」、右の四角が「予測値」であり、予測モデルに既知のデータを入力することで、予測値が出力されるイメージです。
また、予測には大きく分けて「分類(カテゴリの予測)」と「回帰(連続値の予測)」の2種類があります。

分類はインフルエンザの陰性/陽性や、顧客の来店/非来店や、画像から猫・犬・猿を分類するように有限個の種類を当てるような目的で使います。一方で、回帰というのは株価や売上や倒産リスクなど数値を当てるような目的に使います。
予測が必要なケース
予測モデルは、将来の事象や未知の情報を推定する必要がある多くの場面で活用されます。以下のようなケースが代表的です:
- 売上予測:過去の販売実績やキャンペーン情報などをもとに、来月・来季の売上を予測
- 需要予測:物流や在庫管理において、製品や資材の需要量を見積もる
- 離脱予測:サービスを利用しなくなる顧客を事前に検知し、対策を講じる
- 与信判断:金融機関における貸し倒れリスクの評価
- 医療診断支援:患者のデータをもとに、特定の疾患の可能性を予測
- 価格推定:不動産や中古車などの市場価格を算出
このように、予測モデルはさまざまな業種・業界において、意思決定を支援する強力なツールとして活用されています。
予測をするにあたって必要なこと
予測モデルを構築するためには、以下のような準備と処理が必要です。
- データの収集と整備:信頼できるソースから十分な量のデータを収集し、フォーマットの統一や重複削除、ノイズ除去などの処理を行います。
- 教師信号(目的変数)の設定:何を予測したいのか(売上、分類ラベルなど)を明確にし、それに対応する目的変数(ターゲット)を定義します。
- 説明変数の選定:目的変数に影響を与えると考えられる変数(特徴量)を選定します。これらは数値・カテゴリ・日付など様々な形式を取り得ます。
- データの分割:モデルの汎化性能を測るため、データを訓練用・検証用・テスト用に分割します。ホールドアウトやクロスバリデーションの手法がよく用いられます。
これらの準備段階は、モデルの性能に大きく影響を与えるため、丁寧に行うことが重要です。
予測モデルの種類
ここでは、代表的な予測モデルを紹介します。それぞれのモデルには特性があり、データや課題に応じて使い分けることが重要です。
回帰分析と重回帰分析
回帰分析は、数値予測を行うための基本的な手法です。単回帰分析では、目的変数と1つの説明変数の関係をモデル化します。一方、重回帰分析は複数の説明変数を用いて予測精度を高めます。

リッジ回帰とラッソ回帰
重回帰分析では、多数の説明変数があると過学習のリスクが高まります。これを防ぐために、正則化手法であるリッジ回帰(L2正則化)やラッソ回帰(L1正則化)が使われます。ラッソは特徴量選択の効果も持ち合わせており、重要な変数の抽出にも役立ちます。
ロジスティック回帰と判別分析
目的変数がカテゴリ(例:yes/no)の場合には、ロジスティック回帰がよく使われます。また、判別分析(LDAやQDA)は、各クラスの分布を前提として分類を行います。
サポートベクターマシン(SVM)
SVMは、マージン(分類境界からの距離)を最大化することで、汎化性能の高い分類器を作ります。カーネル法を用いることで、非線形なデータにも対応できます。
k近傍法(k-NN)
k-NNは非常にシンプルなアルゴリズムで、学習フェーズはなく、予測時に近傍のk点のラベルで多数決を取ります。特徴量のスケーリングが重要です。
決定木とランダムフォレスト
決定木は直感的で可視化しやすいモデルですが、過学習しやすい特徴があります。ランダムフォレストは複数の決定木を組み合わせることで、バギングにより汎化性能を向上させます。
LightGBM
LightGBMは勾配ブースティングの手法の一つで、大規模なデータや高次元データでも高速に学習できる点が特徴です。カテゴリ変数の自動処理や精度の高さから、実務で広く使われています。
モデルの評価について
予測モデルを評価する際には、モデルがどれだけ正確に予測できているか、また過学習や過少学習が起きていないかを確認することが重要です。目的に応じて適切な評価指標を選びましょう。
回帰モデルの評価指標
- RMSE(Root Mean Squared Error):誤差の二乗平均平方根。誤差の大きさを直感的に把握しやすい。
- MAE(Mean Absolute Error):誤差の絶対値の平均。外れ値の影響を受けにくい。
- R²スコア(決定係数):モデルの説明力を表す指標。1に近いほど良い。
分類モデルの評価指標
- Accuracy(正解率):全体のうち正しく分類された割合。
- Precision / Recall / F1スコア:クラスごとの正確さや再現率を重視した評価。
- AUC(Area Under the Curve):ROC曲線の下の面積。分類の優劣をバランスよく評価できる。
評価時の注意点
- ホールドアウト検証:訓練データとテストデータを分けて評価。
- クロスバリデーション:データを複数に分割して繰り返し学習・検証を行い、汎化性能を高める。
正しい評価指標を選ぶことで、実用性の高いモデルの構築が可能になります。
予測モデルを構築できるツール
予測モデルを構築するためのツールにはさまざまなものがあります。それぞれに特徴があり、用途やユーザーのスキルレベルに応じて選択されます。
Python
Pythonは、機械学習やデータ分析の分野で最も人気のある言語の一つです。scikit-learn、pandas、XGBoost、LightGBM、TensorFlow、PyTorchなど、予測モデル構築に使えるライブラリが豊富に揃っています。
R
Rは統計解析に特化した言語で、回帰分析や分類、モデル評価などの機能が充実しています。caretやrandomForest、glmnet、xgboostなどのパッケージがよく使われます。
その他のツール
- Excel:単純な回帰や線形モデルの学習には使用可能。統計ツールアドインなどを使うことで手軽に解析ができます。
- RapidMiner / Orange:GUIベースで機械学習モデルを構築できるツール。プログラミング不要で初心者にも扱いやすい。
- Google Colab:Pythonをクラウド上で動かせる環境で、ライブラリも事前に用意されているため、環境構築なしで始められます。
- AutoMLツール(Google AutoML, DataRobot, H2O.aiなど):特徴量エンジニアリングからモデル選定・チューニングまで自動化されたプラットフォーム。
これらのツールを活用することで、初心者から上級者まで自分に合った形で予測モデルの構築を進めることができます。
おわりに
予測モデルは多種多様ですが、それぞれに得意不得意があります。前処理と特徴量エンジニアリングを丁寧に行い、適切な評価を重ねながら、自分に最適なモデルを選んでいくことが重要です。