こんにちは、デジタルボーイです。今回はランダムフォレストによる分類問題をPythonとscikit-learnを使って構築したいと思います!
僕のランダムフォレスト(random-forest)への印象ですが、決定木よりも複雑なモデルのため使いにくく、かつ、LightGBMなどの勾配ブースティング木に比べて精度も高くないケースが多いです。僕自身の分析コンサル場面では、直感的な説明のしやすさを重視するケースは決定木や重回帰分析、とにかく予測精度を上げたい場合はLightGBM、という使い分けのため、ランダムフォレストを最終モデルとして納品するうことはあまりありません。
じゃあ、データサイエンティストにとって、ランダムフォレストは勉強しなくていいのかというと、そういうことではないと考えています。というのも、ランダムフォレストではバギング(bagging)という方法論が使われますが、この考え方は、データサイエンティストが予測精度を上げるために非常に重要な考え方となるからです。
なので、今夏はバギングについても触れながらpythonを使ったランダムフォレストについて、解説したいと思います!

デジタルボーイです。
データサイエンス歴20年以上のおっさんです。中小企業診断士として、データサイエンス、WEBマーケティング、SEOに関するデータ分析、コンサルティングの仕事をしています。自己紹介の詳細はコチラ
ランダムフォレスト(random forest)とは?
経営判断でも、議会政治でも、クラス会でも、「1人の意見で判断するより、多くの人の意見を集めたほうが正しい判断ができる」 という考え方は、民主主義の根本的な考え方といえます。1人の意見で何かを決定する場合、その人の意見が必ず正しければいいですが、そうでない場合、どうしても偏った判断をしてしまうからです。だからこそ、多少は時間がかかっても、多くの人の意見を集約することが重要になって来るんですね。
このことは、実は、予測モデルでも当てはまります。予測モデルを構築する際、単体のモデルよりも、複数のモデルを組み合わせた方が高精度な予測ができることがあります。そしてこの、「複数のモデルを組み合わせる手法」のことをアンサンブル学習と言います。
そして、ランダムフォレストは、多数の決定木(ディシジョンツリー)を組み合わせて予測を行うアンサンブル学習の手法を指します。一つの決定木だけでは過学習しやすく、予測が不安定になりがちですが、複数の決定木の予測を統合することで、より安定した予測を行うことができるだとう、という理屈です。予測モデルの民主主義ですね!
ランダムフォレストの直感的な理解
ランダムフォレストは、以下のような特徴を持っています。
- 過学習しにくい:決定木を多数組み合わせることで、データに過剰に適合するリスクを低減できます。
- 高い精度:バギング(ブートストラップサンプリング)と特徴量のランダム選択により、多様な決定木を作成し、予測精度を向上させます。
- 特徴量の重要度を評価できる:どの特徴量が予測にどれくらい影響しているかを数値化できます。
ランダムフォレストは複数の決定木をいくつもつくり、そのモデルたちから多数決を取ることで、予測を行います。この際、「何個も決定木を作っても同じモデルになるんちゃう?」と思われるでしょう。そのため、同じモデルにならないための手続きがあります。
それが、次の2つのサンプリングの手法です。この2つのサンプリングによって、モデルに投入するデータをちょっとずつずらして、別々のモデルを作る処理を実施します。
- データをサンプリングする(復元抽出/ブートストラップサンプリング)
- 特徴量をランダムサンプリングする。
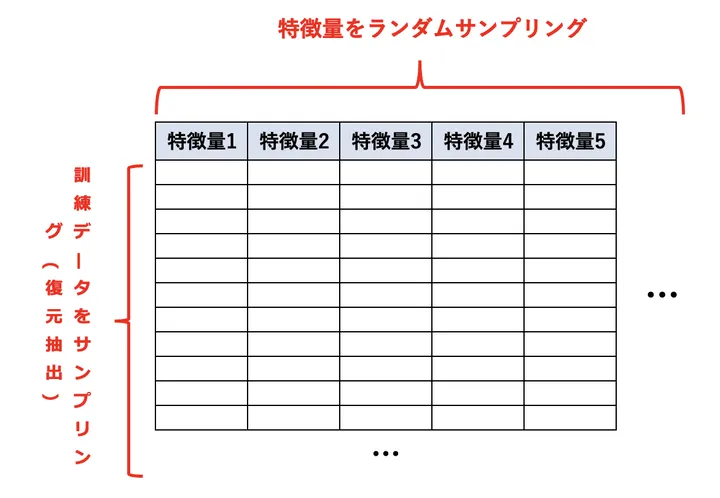
①の「データをサンプリング」は、図の左側のサンプリングです。②の「特徴量をランダムサンプリング」するというのは、図の上側のサンプリングに当たります。
そして、複数の決定木を作った後に結果を多数決します。
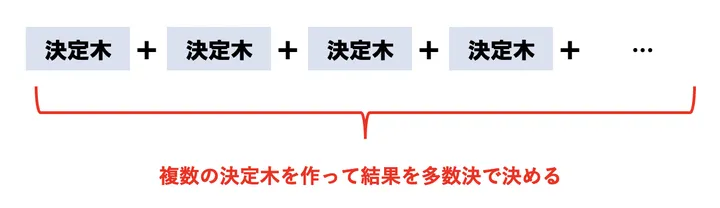
これによって、元々は同じデータにも関わらず、別々のモデルを複数(sklearnだとデフォルトで100個)作り、結果を多数決で決めます。これがランダムフォレストの基本的な流れです。
ちなみにこのようにデータをランダムサンプリングしながら複数のモデルを作成し、最後に多数決で予測値を決定する手法はバギング(bagging)と言います。予測モデルを構築する際は、非常に需要な考え方になるので、覚えておいてそんはないと思います!
ランダムフォレストの応用場面
ランダムフォレストは、実際のデータ分析の現場でも幅広く使われています。いくつかの具体的な応用例を見てみましょう!
1. 医療分野
- 病気の診断:患者の症状データをもとに、病気の可能性を予測(例: がん診断)。
- 遺伝子データの解析:どの遺伝子が疾患に関連しているかを特定。
2. 金融分野
- 不正取引の検出:クレジットカードの取引データから、不正使用の兆候を発見。
- 顧客の信用スコアリング:ローンの審査で、過去の返済履歴や収入データを分析し、信用リスクを評価。
3. マーケティング
- 顧客の購買予測:ECサイトでの過去の購買履歴から、次に購入する可能性の高い商品を予測。
- ターゲット広告:ユーザーの行動データを基に、最適な広告を配信。
4. 製造・品質管理
- 異常検知:工場のセンサーからのデータをもとに、異常を検出し、故障の予兆を見つける。
- 品質管理:製品の品質データを分析し、不良品を予測。
5. 環境・気象予測
- 気象予測:過去の気象データから、気温や降水量を予測。
- 森林火災のリスク評価:気温や湿度データを分析し、火災が発生するリスクを評価。
こんな感じで、ランダムフォレストはさまざまな分野で活用できる機械学習手法といえます!
必要なライブラリのインポート
ランダムフォレストを使うには、scikit-learnライブラリを利用します。まだインストールしていない場合は、以下のコマンドでインストールしてください
pip install numpy pandas seaborn matplotlib scikit-learnpipを使ったインストール方法がわからない場合はこちらをご覧ください。



では、必要なライブラリをインポートしましょう。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, mean_squared_error
これで準備完了です!次に、実際にk近傍法を使ったモデルの実装を行いましょう。
データの項目の確認と概要の確認
今回は、seaborn に組み込まれている タイタニック号の乗客データ を使って、ランダムフォレストの分析に向けた前準備を進めていきます。まずは、どのような項目があるのか、そしてデータ全体の様子をざっくりと確認しておきましょう。
以下のコードを実行すると、タイタニックデータの最初の数行が表示され、各列にどのようなデータが含まれているかを確認することができます。
# データの読み込み
df = sns.load_dataset("titanic")
# データの先頭5行を表示
df.head()
コード解説
sns.load_dataset("titanic")は、組み込みの「titanic」データセットを読み込んでいます。df.head()は、データの最初の5行を表示し、全体像をつかむのに便利です。
以下のような結果が出力されます。
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | male | 22 | 1 | 0 | 7.25 | S | Third | man | True | nan | Southampton | no | False |
| 1 | 1 | female | 38 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 1 | 3 | female | 26 | 0 | 0 | 7.925 | S | Third | woman | False | nan | Southampton | yes | True |
| 1 | 1 | female | 35 | 1 | 0 | 53.1 | S | First | woman | False | C | Southampton | yes | False |
| 0 | 3 | male | 35 | 0 | 0 | 8.05 | S | Third | man | True | nan | Southampton | no | True |
特徴量(説明変数)の日本語訳と簡単な説明は以下の通り。
| 英語の項目名 | 日本語訳 |
|---|---|
| survived | 生存フラグ(1 = 生存、0 = 死亡) |
| pclass | 乗客クラス(1 = 上級, 2 = 中級, 3 = 下級) |
| sex | 性別 |
| age | 年齢 |
| sibsp | 同乗している兄弟・配偶者の数 |
| parch | 同乗している親・子どもの数 |
| fare | 乗船料金 |
| embarked | 乗船した港(C = シェルブール, Q = クイーンズタウン, S = サウサンプトン) |
| class | 乗客クラス(カテゴリ名。pclassとほぼ同じ意味) |
| who | 乗客の属性(man, woman, child) |
| adult_male | 成人男性かどうか(True / False) |
| deck | 客室のデッキ(甲板の位置) |
| embark_town | 出港地(都市名。embarkedの補足) |
| alive | 生存かどうか(yes / no) |
| alone | 一人で乗船していたかどうか(True / False) |
簡単にデータの基本統計量を見てみましょう。
# 数値データの統計的な要約を表示
df.describe()以下は特徴量の内、連続変数のデータです。
| survived | pclass | age | sibsp | parch | fare | |
|---|---|---|---|---|---|---|
| count | 891 | 891 | 714 | 891 | 891 | 891 |
| mean | 0.383838 | 2.30864 | 29.6991 | 0.523008 | 0.381594 | 32.2042 |
| std | 0.486592 | 0.836071 | 14.5265 | 1.10274 | 0.806057 | 49.6934 |
| min | 0 | 1 | 0.42 | 0 | 0 | 0 |
| 25% | 0 | 2 | 20.125 | 0 | 0 | 7.9104 |
| 50% | 0 | 3 | 28 | 0 | 0 | 14.4542 |
| 75% | 1 | 3 | 38 | 1 | 0 | 31 |
| max | 1 | 3 | 80 | 8 | 6 | 512.329 |
分析の目的とゴール
今回の分析の目的は、「タイタニック号の乗客データをもとに、生存者を予測するモデルを構築すること」です。ランダムフォレストを使い、「どのような特徴を持つ乗客が生存しやすかったのか?」を探りながら、最適なモデルを作成していきます。
具体的なゴールは以下のとおりです。
- 生存確率を予測するモデルを構築する
乗客の年齢・性別・客室クラスなどのデータをもとに、生存の可否を分類する機械学習モデルを作ります。 - 特徴量の重要度を確認する
どの特徴(年齢・性別・料金など)が生存率に大きな影響を与えたのかを、ランダムフォレストの特徴量重要度を使って分析します。 - 最適なモデルの構築を目指す
最終的には、モデルの精度を評価し、できるだけ高い正解率を持つ予測器を作ることを目標とします!
それでは、データの前処理を行い、モデルの実装に進みましょう。
モデルの実装
まずは、ランダムフォレストを用いた分類モデルを実装していきます。今回は、簡単のため、モデルに使いやすいデータを選別してモデルに投入することにします。流れとしては、データの前処理を行い、学習用とテスト用に分割した後、モデルを構築するところまでを進めます。評価は後で行うため、ここでは評価指標の算出は不要です。
# 必要な列を選択
df = df[['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked']]
df = df.dropna() # 欠損値を削除
# カテゴリ変数を数値に変換
df['sex'] = df['sex'].map({'male': 0, 'female': 1})
df['embarked'] = df['embarked'].map({'C': 0, 'Q': 1, 'S': 2})
# 特徴量とターゲットを分割
X = df.drop(columns=['survived'])
y = df['survived']
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ランダムフォレストモデルの作成と学習
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 予測(評価は後で行う)
y_pred = model.predict(X_test)
コード解説
survived(生存 or 死亡)と、特徴量として使えそうなデータのみを選択(pclassやsexなど)。- 欠損値を
dropna()で削除 し、モデルに適した形に整える。 sexやembarked(乗船地)を数値データに変換 し、機械学習モデルで扱いやすくする。train_test_splitで訓練データとテストデータを8:2に分割 し、モデルの学習と評価の準備を整える。RandomForestClassifierを使ってモデルを作成し、学習データでfit()を実行 することで訓練を行う。- テストデータに対して
predict()を実行し、予測を取得
モデルの評価
モデルがどの程度正しく予測できているのかを確認するために、いくつかの評価指標を計算します。今回のランダムフォレストは分類モデルなので、正解率(Accuracy)、適合率(Precision)、再現率(Recall)、F1スコア(F1-score)、混同行列(Confusion Matrix)を用いて評価を行います。
正解率(Accuracy)は、予測がどれだけ正しく分類されているかを示す指標です。全体の中で正しく予測された割合を算出し、モデルの基本的な精度を把握できます。適合率(Precision)と再現率(Recall)、F1スコア(F1-score)も重要な指標です。適合率は「生存」と予測された人の中で、実際に生存していた人の割合を示します。再現率は、実際に生存していた人の中で、どれくらい「生存」と正しく予測されたかを表します。これら2つのバランスを考慮した指標がF1スコアであり、モデルの全体的な性能を評価する際に役立ちます。
また、混同行列(Confusion Matrix)を確認すると、正解と不正解の内訳をより詳細に把握できます。「生存と予測して当たった数」「死亡と予測して当たった数」「間違った予測の数」などが一目で分かるため、モデルがどのような間違いをしているのかを視覚的に理解するのに便利です。
ここら辺の分類モデルの評価については決定木の解説で詳しく書いてあるので、よかったらみてみてください。

では、実際にコードを実行して、モデルの評価をしてみましょう。
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
# 正解率
accuracy = accuracy_score(y_test, y_pred)
# Precision, Recall, F1-score
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
# 混同行列
conf_matrix = confusion_matrix(y_test, y_pred)
# 結果を出力
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print(f"F1-score: {f1:.2f}")
print("Confusion Matrix:")
print(conf_matrix)コード解説
accuracy_score(y_test, y_pred)で、モデルの 正解率(Accuracy) を算出。これは全データのうち、どれくらいの割合で正しく予測できたかを示す。precision_score(y_test, y_pred)で 適合率(Precision) を計算。生存と予測された人のうち、本当に生存していた割合がわかる。recall_score(y_test, y_pred)で 再現率(Recall) を計算。実際に生存していた人を、どれだけ正しく「生存」と予測できたかを示す。f1_score(y_test, y_pred)は、Precision と Recall のバランスを考慮した指標。モデルの全体的な性能を示す指標としてよく使われる。confusion_matrix(y_test, y_pred)で 混同行列(Confusion Matrix) を算出。予測の内訳を確認できる。
結果は以下の通りです。
Accuracy: 0.77
Precision: 0.76
Recall: 0.70
F1-score: 0.73
Confusion Matrix:
[[66 14]
[19 44]]では、具体的な結果についてみていきましょう。
まず、正解率(Accuracy) は 0.77 でした。これは、全体の77%のデータについて正しく予測できたことを意味します。僕のコンサル場面では、70%以上の正解率が出ていれば、「初手の精度でこの結果だったら、まずまずの精度かな?」と考えます。
次に、適合率(Precision) は 0.76 です。これは「生存(1)」と予測されたうち、実際に生存していた割合を示します。つまり、「生存」とモデルが判断した人の76%が実際に助かっていたことを意味します。適合率が高いほど、誤って「生存」と予測するケース(False Positive)が少ないということになります。
再現率(Recall) は 0.70 でした。これは、実際に生存していた人のうち、どれだけ正しく「生存」と予測できたかを表します。つまり、生存者のうち70%は正しく生存と判定されたが、残り30%は誤って「死亡」と予測されてしまったということになります。再現率が低い場合、本来助かるはずの人を「助からなかった」と誤認識するリスクが高くなります。
F1スコア(F1-score) は 0.73 でした。これは、Precision(適合率)と Recall(再現率)のバランスを考慮した指標です。今回の結果では、適合率と再現率のどちらもそこそこの値が出ており、全体としてバランスの取れたモデルになっていると言えます。
最後に、混同行列(Confusion Matrix) を見て、より詳細なモデルの動作を確認しましょう。
特徴量の重要度を見てみよう
では、モデルでどの特徴量が予測に効いたのか見てみましょう。これはscikit-learnのpermutation_importanceという機能で、sklearnが自動的にモデルから説明変数を抜き差しして予測精度の変動具合から予測にどれくらい貢献しているのかを数値化してくれるものになります。
from sklearn.inspection import permutation_importance
plt.rcParams["font.family"] = "Hiragino sans"
# 予測精度ベースの特徴量重要度を計算
perm_importance = permutation_importance(model, X_test, y_test, n_repeats=10, random_state=42)
# 特徴量の名前を取得
feature_names = X.columns
# グラフ化
plt.figure(figsize=(8, 5))
plt.barh(feature_names, perm_importance.importances_mean, color="lightcoral")
plt.xlabel("予測精度の変化量")
plt.ylabel("特徴量")
plt.title("ランダムフォレストにおける特徴量の重要度(Permutation Importance)")
plt.show()
コード解説
class_names = data.target_names: クラス分類用のラベル名をセット。feature_names = data.feature_names: 決定木が使う特徴量の名前をセットplot_tree(clf, feature_names=feature_names, class_names=class_names, filled=True)- 決定木を可視化 する関数です。特徴量やクラス名を表示し、色付きでツリーを描画します。
結果は以下の通りです。
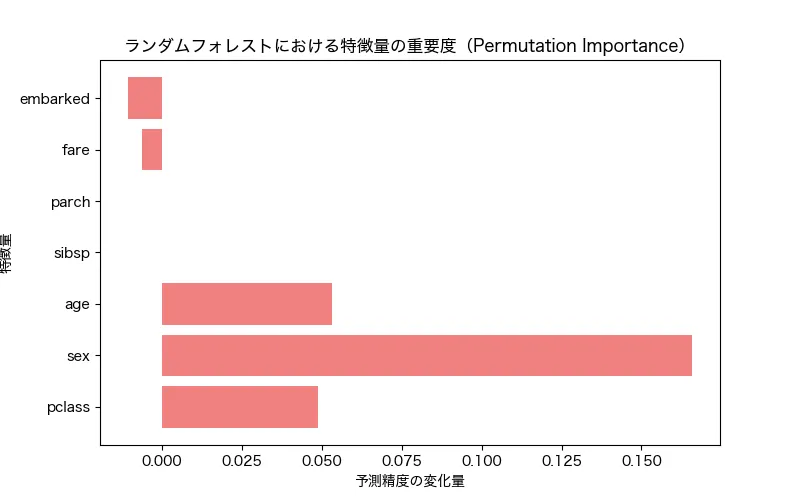
実際の説明変数の重要度の結果をみていきましょう。最も影響が大きかったのは「性別(sex)」で、スコアは0.166と他を大きく引き離しており、続いて、「年齢(age)の0.053でした。実際のタイタニックの救助活動でも「女性と子どもが優先された」と伝えられています。定員に対して救命具やボートが足りなかった中、女性や子供が優先され救助されたことが、データでも読み取れますね続いて、「乗客クラス(pclass)」は0.049というスコアでした。身分の高い人が優先的に救助されたのかもしれませんね!
複数の決定木を作る際、いくつ作れば良い?
ランダムフォレストをsk-learnで実行する際、次のようにn_estimatorsを指定することができます。n_estimatorsは内部で作成する決定木の数です。デフォルトでは100となります。
model = RandomForestClassifier(
n_estimators=n,
max_features='sqrt', # 固定
min_samples_split=2, # 固定
random_state=42
)ここで、n_estimatorsの数値を変えながらタイタニックデータの予測精度の違いを実験してみましょう。
実験内容
- データ:タイタニック
- n_estimatorsを1から120まで5刻みで実施
- 評価指標:正解率
結果は以下になりました。
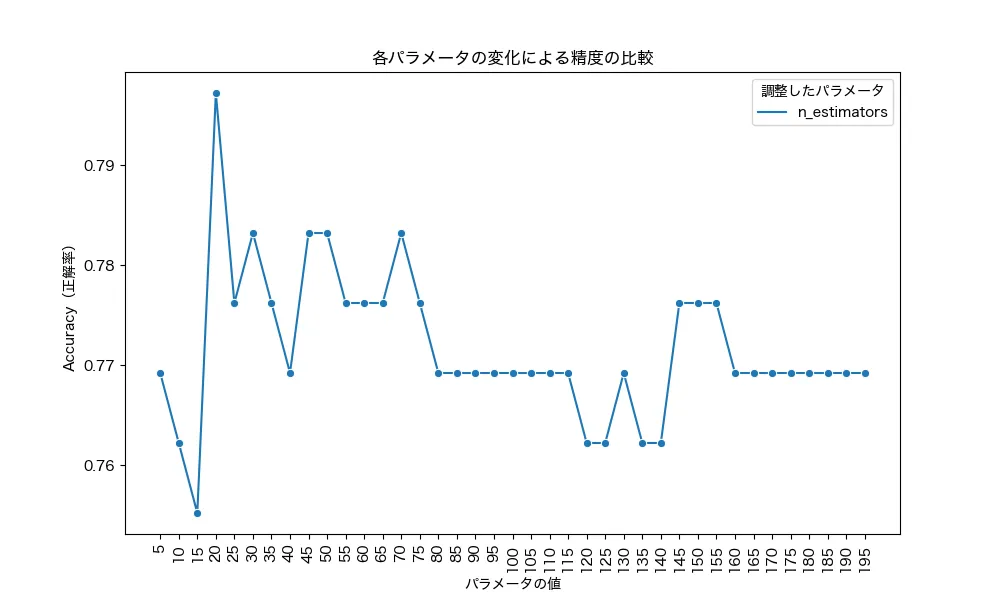
横軸はn_estimatorsの数、縦軸は正解率です。n_estimatorsが20の時がもっとも高く、75以降は下げ止まり、145~155までは若干改善されているようですね。ここから、今回のデータでは50〜70くらいが一つの目安といえるかもしれません。デフォルトが100なので、100前後でいくつか変更しながら見てみると良いかもしれませんね。
まとめ
今回は、ランダムフォレストを使ったタイタニックデータの分類モデルの構築と評価を行いました。ランダムフォレストは決定木の発展モデルということができ、決定木から予測精度を上げる際の自然な選択肢と言えるでしょう。ぜひ、活用してみてください!