
こんにちは、デジタルボーイです。備忘録がてら、macとLinuxにpipでpandasをインストールするための手順を、まとめておきます。
記事を書いた人

デジタルボーイです。
データサイエンス歴20年以上のおっさんです。中小企業診断士として、データサイエンス、WEBマーケティング、SEOに関するデータ分析、コンサルティングの仕事をしています。自己紹介の詳細はコチラ
お時間のない人のための、結論!!
pandasのインストールは以下のコマンドで実行できます。
pip install pandas目次
環境設定
- OS: macOS
- Python: 3.11.0
最新版のpandasをインストールする手順
pandasは、Pythonでデータ分析を行うための超超超定番ライブラリです。データの操作やファイルの入出力のできる便利ツールといったところです。やや癖のある操作方法ですが、なれると使いやすい必須のツールといえますね!
以下の手順でインストールできます。
まず、念のため、pipを最新版にアップデートしておきます。
% pip install --upgrade pip次に、pandasをインストールします。
% pip install pandasインストールされたバージョンを確認するには、以下のコマンドを使用します。
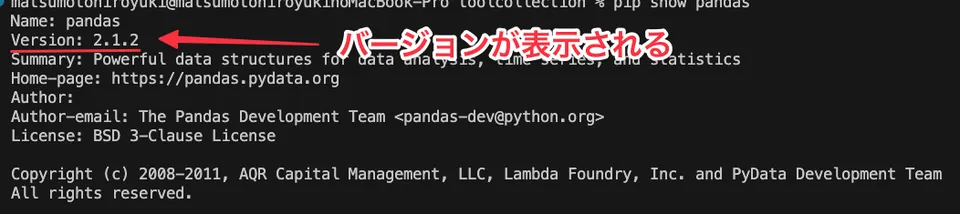
% pip show pandas
Name: pandas
Version: 2.1.2
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
Author:
Author-email: The Pandas Development Team <pandas-dev@python.org>
License: BSD 3-Clause License
...僕のPCの画面ではこんな感じです。
バージョンを指定してpandasをインストールする手順
特定のバージョンのpandasをインストールしたい場合は、次の手順を使用します。pip index versionsでインストール可能なバージョンを確認できます。
% pip index versions pandas
WARNING: pip index is currently an experimental command...
pandas (2.2.3)
Available versions: 2.2.3, 2.2.2, 2.2.1, 2.2.0, 2.1.4, 2.1.3,...
INSTALLED: 2.1.2
LATEST: 2.2.3バージョンを指定してインストールするには、==x.x.xの形式を使用します。
% pip install pandas==2.1.3pandasの簡単な使用例
以下は、pandasを使用してCSVファイルを読み込み、基本的な操作を行う簡単な例です。
import pandas as pd
import numpy as np
# サンプルデータの生成
np.random.seed(0) # 再現性のため
data = {
'id': range(1, 101),
'age': np.random.randint(20, 70, 100),
'salary': np.random.randint(30000, 100000, 100),
'experience': np.random.randint(0, 30, 100)
}
# DataFrameの作成
df = pd.DataFrame(data)
# データの最初の5行を表示
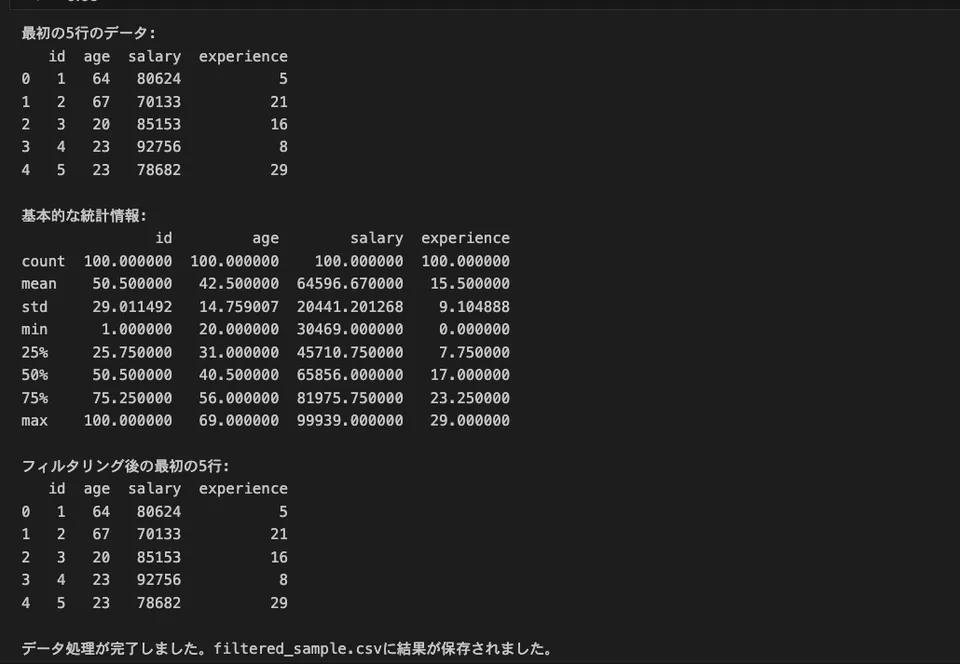
print("最初の5行のデータ:")
print(df.head())
# 基本的な統計情報を表示
print("\n基本的な統計情報:")
print(df.describe())
# 特定の列でフィルタリング(例:給与が60000以上)
filtered_df = df[df['salary'] > 60000]
# フィルタリング結果の最初の5行を表示
print("\nフィルタリング後の最初の5行:")
print(filtered_df.head())
# 結果を新しいCSVファイルに保存
filtered_df.to_csv('filtered_sample.csv', index=False)
print("\nデータ処理が完了しました。filtered_sample.csvに結果が保存されました。")適当に、ランダムなデータを生成し、統計量の算出や、データのフィルタリングを実行しています。こんな感じのアウトプットがでるはずです。
まとめ
以上が、pipを使用したpandasライブラリのインストール手順と簡単な使用例でした!pandasはデータ分析や機械学習をやる上で、ほぼ必須のツールです。ぜひ活用してみてください。